大型语言模子(LLMs)正在迅速逼近当代盘算硬件的极限。比方,据估算,训练GPT-3大约斲丧了1300兆瓦时(MWh)的电力,预测表现未来模子可能需要都会级(吉瓦级)的电力预算。这种需求促使人们探索逾越传统冯·诺依曼
|
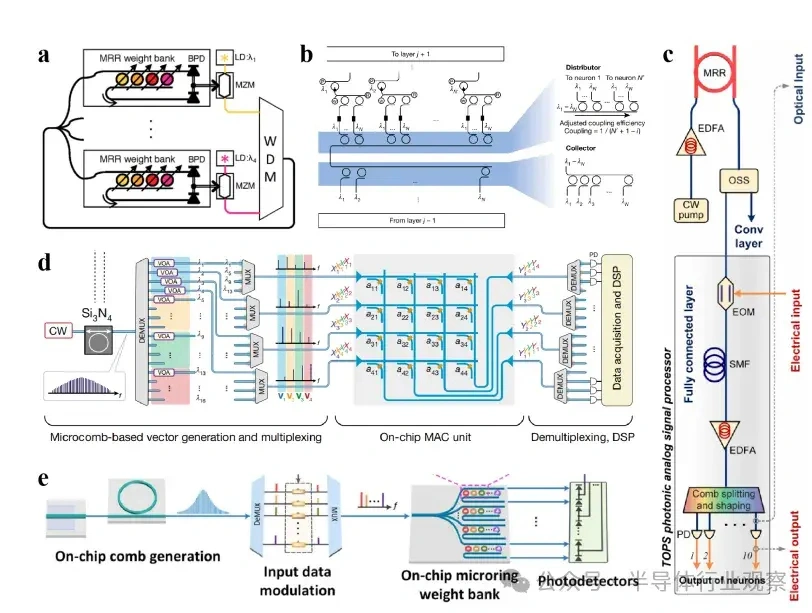
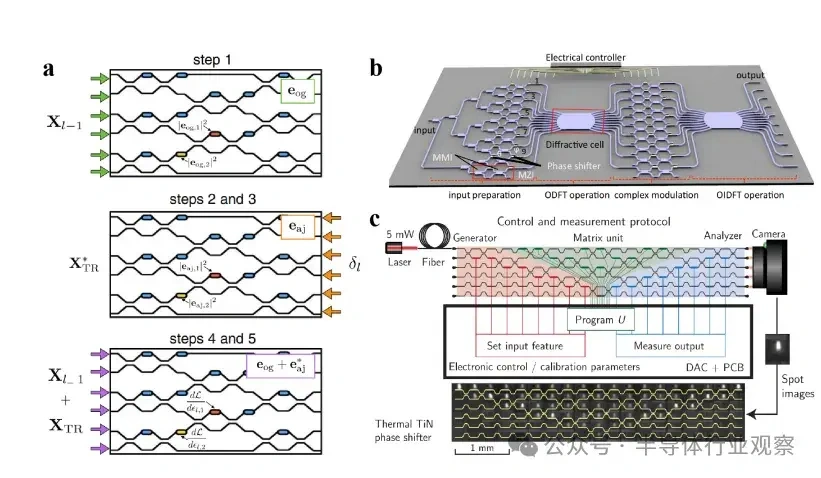
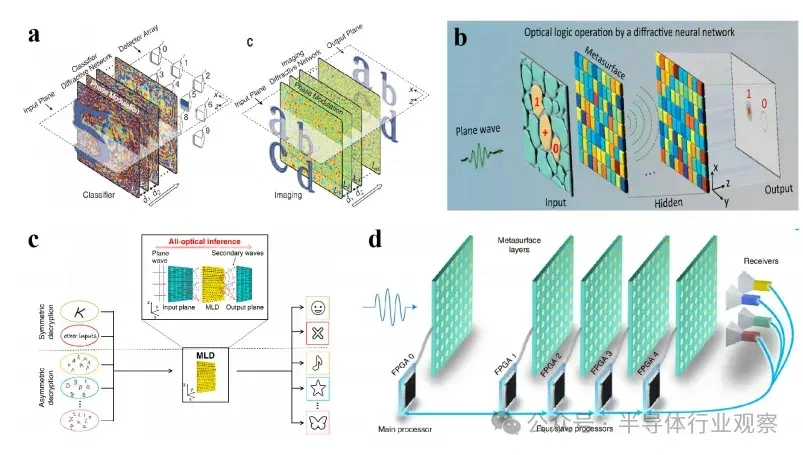
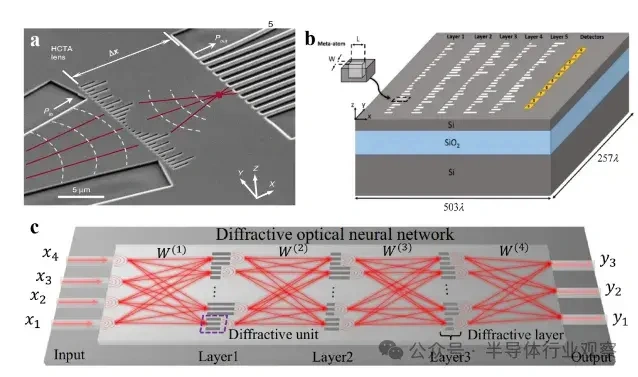
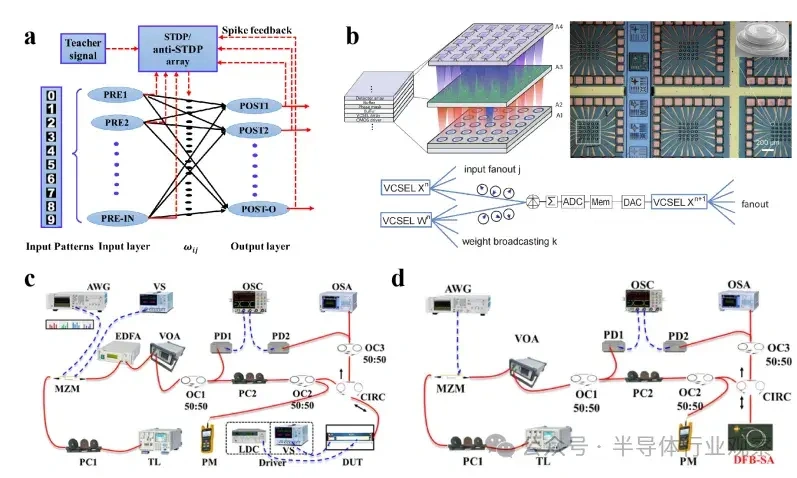
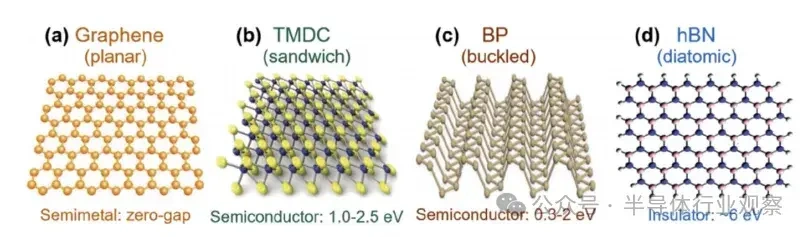
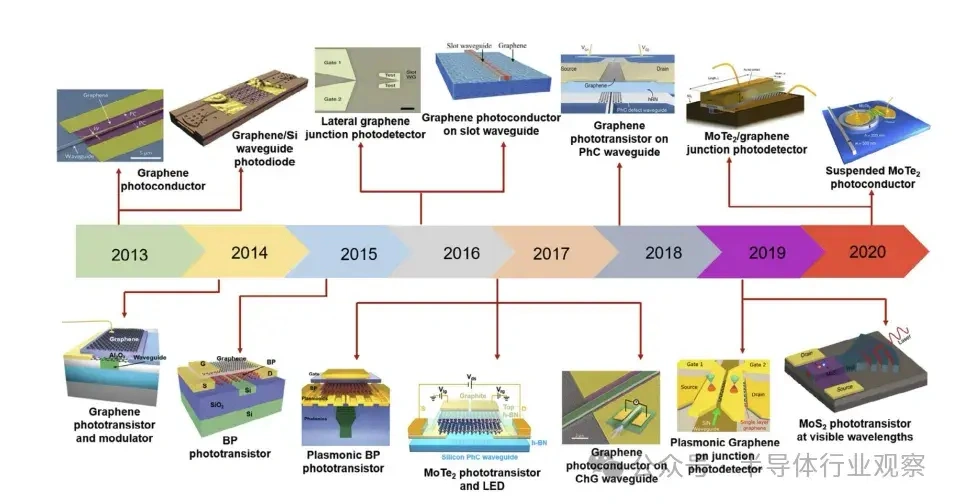
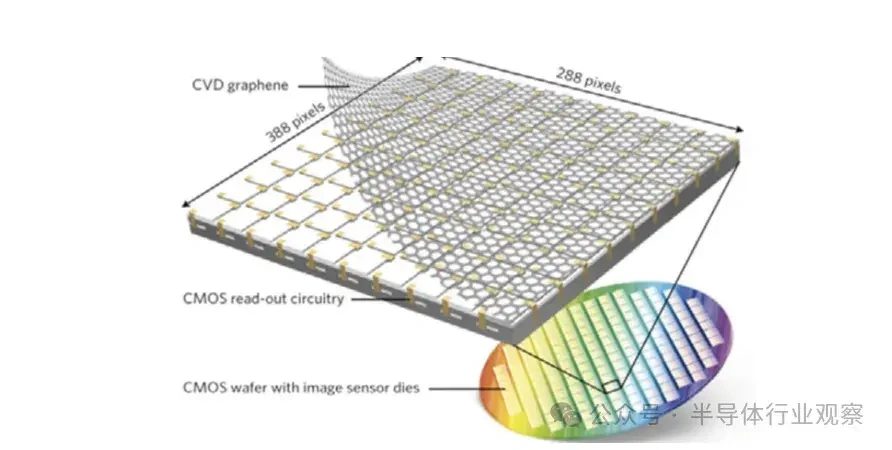
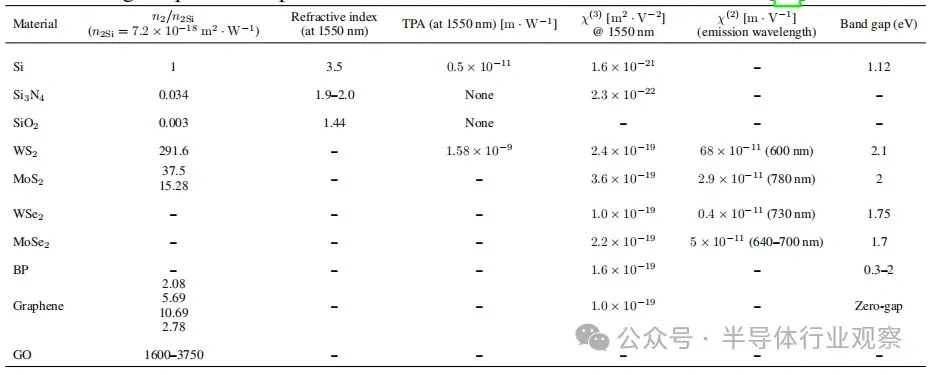
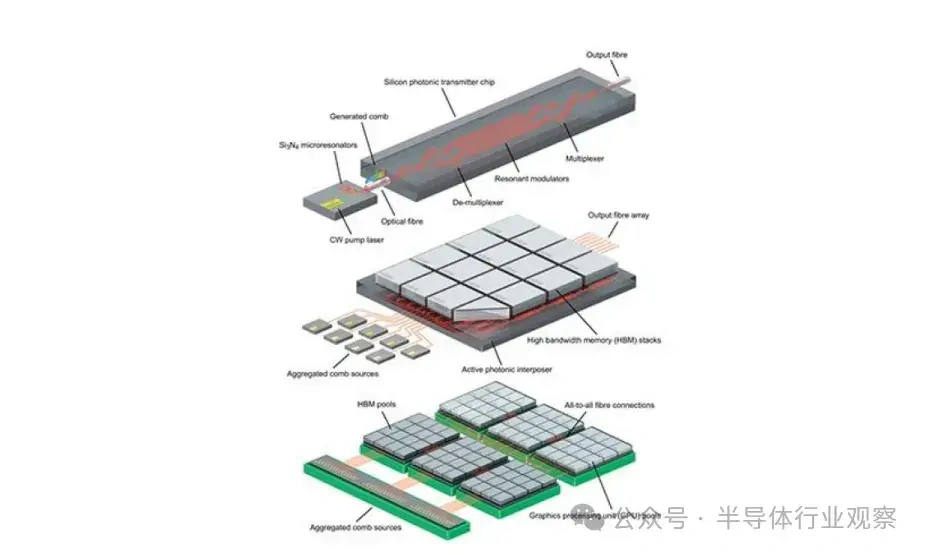
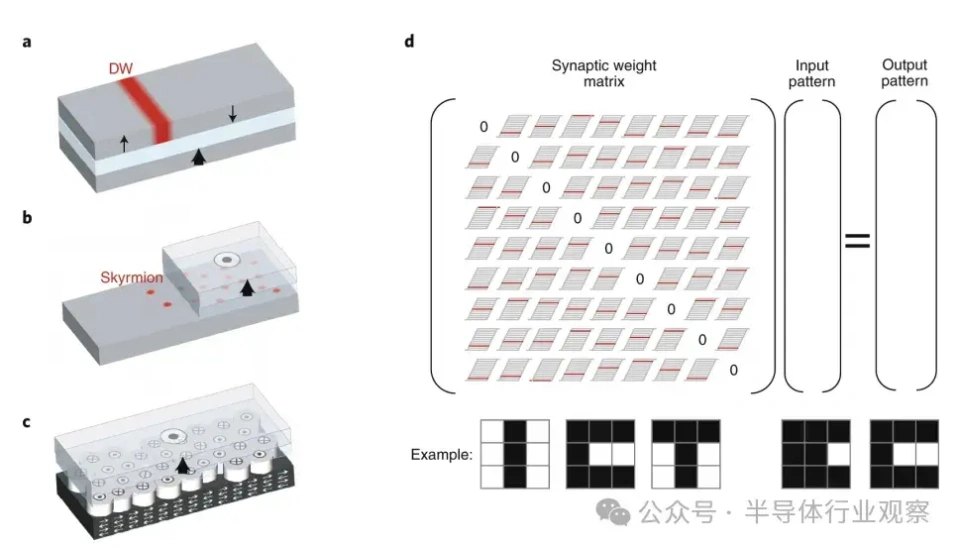
大型语言模子(LLMs)正在迅速逼近当代盘算硬件的极限。比方,据估算,训练GPT-3大约斲丧了1300兆瓦时(MWh)的电力,预测表现未来模子可能需要都会级(吉瓦级)的电力预算。这种需求促使人们探索逾越传统冯·诺依曼架构的盘算范式。 本综述调查了为下一代生成 式AI盘算优化的新兴光子硬件。我们批评辩说 了集成光子神经收集 架构(如马赫-曾德干涉仪阵列、激光器、波长复用微环谐振器),这些架构可以或许实现超高速矩阵运算。同时,我们也研讨 了有前景的替代类神经设备,包罗脉冲神经收集 电路和混淆自旋-光子突触,它们将存储与盘算融会 在一起 。本文还综述了将二维材料(如石墨烯、过渡金属二硫族化合物,TMDCs)集成进硅基光子平台,用于可调制器和片上突触元件的研讨 希望。 我们在这种硬件背景下分析了基于Transformer的大型语言模子架构(包罗自注意力机制和前馈层),指出了将动态矩阵乘法映射到这些新型硬件上的策略与挑衅。随后,我们剖析了主流大型语言模子的内部机制,比方chatGPT、DeepSeek和Llama,凸起 了它们架构上的异同。 我们综合了当前最先辈的组件、算法和集成方法 ,夸大了在将此类体系扩展到百万级模子时的症结 希望与未解标题。我们发现,光子盘算体系在吞吐量和能效方面有可能逾越电子处置惩罚器几个数目级,但在长凹凸 文窗口、长序列处置惩罚所需的存储与大规模数据集的生存方面仍需技能冲破 。本综述为AI硬件的发展供给 了一条清楚的蹊径图,夸大了先辈光子组件和技能在支持未来LLM中的症结 浸染 。 弁言 频年 来基于Transformer的大型语言模子(LLMs)的快速发展极大地进步了对盘算基础设施的需求。训练最先辈的AI模子现在需要伟大 的盘算与能耗资本 。比方,GPT-3模子在训练时代 估计 斲丧了约1300兆瓦时的电力,而行业预测表白 ,下一代LLM可能需要吉瓦级的电力预算。这一趋势与大规模GPU集群的使用同时涌现 (比方,Meta训练Llama 4时使用了超过10万个NVIDIA H100 GPU的集群)。与此同时,传统硅基芯片正接近其物理极限(晶体管特性尺寸已达约3纳米),冯·诺依曼架构也受限于“存储器–处置惩罚器”瓶颈,从而限制 了速度 与能效。这些身分 共同凸显出LLMs日益增长 的盘算需求与传统CMOS电子硬件能力之间的鸿沟。 这一挑衅促使人们探索替代盘算范式。光子盘算使用光来处置惩罚信息,天然具有高带宽、超强并行性与极低热耗散等优势。近期在光子集成电路(PICs)上的希望,使得构建神经收集 基本 模块成为可能,比方相干 干涉仪阵列、微环谐振器(MRR)权重阵列,以及用于执行麋集矩阵乘法与乘-加操作的波分复用(WDM)筹划 。这些光子处置惩罚器使用WDM实现了极致的并行性与吞吐能力。 与此同时,将二维材料(如石墨烯与TMDCs)集成入PIC中,催生了超高速的电吸收调制器与可饱和吸收体,成为片上的“神经元”与“突触”。作为光学的增补,自旋电子类神经设备(如磁地道 结和斯格明子通道)供给 非易掉 性突触存储和类神经脉冲行为。这些光子与自旋电子类神经元件从物理机制上实现了存储与处置惩罚的合一,为能效优化的AI盘算开发新门路 。 将基于Transformer的LLM架构映射到这些新型硬件平台上,面临诸多挑衅。Transformer中的自注意力层涉及动态盘算的权重矩阵(query、key和value),这些权重依靠于输入数据。筹划可重构的光子或自旋电路以实现这种数据依靠型操作,正成为活泼研讨 范畴。别的,在光子/自旋子前言中实现模拟非线性(如GeLU激活函数)与归一化还是庞大技能困难。 为应对上述标题,研讨 者提出了许多“硬件感知”的算法筹划谋略,如适用于光子盘算的训练方法 以及能容忍模拟噪声和量化误差的神经收集 模子。 本综述余下部门布局如下: 第2节:先容光子加速器架构,包罗相干 干涉仪收集 、微环权重阵列与基于波分复用的矩阵处置惩罚器; 第3节:探究二维材料在光子芯片上的集成(如石墨烯/TMDC调制器、光子忆阻器); 第4节:分析替代类神经设备,特殊是自旋电子在类神经盘算中的应用; 第5节:总结主流LLM与Transformer架构道理 ,并探究如何将其映射到光子芯片上,夸大在光子与类神经硬件上实现注意力机制与前馈层的策略; 第6节:先容脉冲神经收集 的机制与实现算法; 第7节:指出体系层面的症结 挑衅并预测未来标的目的 。 本综述力图 为下一代AI硬件发展绘制出基于光子与自旋电子技能的完备蹊径图。 光子神经收集 与光子盘算的前沿器件 光子神经收集 (PNN:Photonic neural networks)依托多种光学器件之间的协同浸染 实现高效盘算:微环谐振器使用共振效应举办 波长复用与光频梳生成 ,为多波长旌旗记号 处置惩罚奠基基础 ;马赫-曾德干涉仪(MZI:Mach-Zehnder interferometer)阵列经由过程 相位调制实现光学矩阵运算,是神经收集 中焦点线性变换的症结 元件 ;超构表面 经由过程 亚波长布局调控光波的相位与幅度,能在衍射域内执行高度并行的光学盘算 ;4f体系经由过程 傅里叶变换在衍射域中实现线性滤波功能 ;而新型激光器则经由过程 电光转换机制实现非线性激活功能 。这些器件集成了光场调控、线性变换与非线性响应 能力,构建出高速、低功耗、强并行的全光盘算架构。 本节将先容当前光学神经收集 实现中常用的器件。 微环谐振器 微环谐振器(MRRs)(见图1)的告急性不仅表现在它们在波分复用(WDM)中的浸染 ,还表现在其奇特 的滤波特性 ,比方光频梳生成 。WDM允许不同波长的旌旗记号 在同一 波导中同时流传而不会产生干扰:经由过程 筹划微环的半径与折射率以支持特定的共振波长,满足共振前提 的光将耦合进环形腔体中持续振荡,在透射谱上表现为明显的吸收凹槽。 而光频梳则源于高Q值(低损耗)微腔中的参量振荡:当注入连续波(CW)泵浦激光后,光子会经历非线性效应(如Kerr非线性),从而自觉地产生等间距的光谱线,形成梳状频谱。WDM与频梳生成 的结合,使多波长旌旗记号 可经由过程 共享波导举办 合成与传输,实现波长复用与空间复用的同一。 微环的其他特性 也得到 了使用。比方,使用微环的热光效应,在微环上加入了具有激射阈值的相变材料,实现了雷同神经收集 中ReLU函数的非线性效果。
             |


2025-05-03
2025-03-05
2025-02-26
2025-03-05
2025-02-26


官方手机版

微信公众号

商务合作