
昨夜晚间,思科推出了一款新型路由 ASIC,旨在通过将现稀有 据中心整合到单个统一 的计算 集群中来帮助比特仓运营商克服 功率和容量限制。新宣布 的8223是一款 51.2 Tbps 路由器,搭载其自立 研发的 Silicon One P200 ASIC
|
昨夜晚间,思科推出了一款新型路由 ASIC,旨在通过将现稀有 据中心整合到单个统一 的计算 集群中来帮助比特仓运营商克服 功率和容量限制。 新宣布 的8223是一款 51.2 Tbps 路由器,搭载其自立 研发的 Silicon One P200 ASIC。思科表示,结合 800 Gbps 干系光器件,该平台可支撑 高达 1,000 公里的传输距离。在毗连富足多的路由器后,该架构理论上可实现每秒 3 EB 的总带宽,这足以毗连当今最大的 AI 训练集群。 究竟上,如许的收集 将可以或许支撑 包含数百万个 GPU 的多站点部署,但正如您所料,实现这种级别的 带宽并未便宜 ,须要数千个路由器才华使其全体 工作。对于不须要那么快毗连的客户,思科表示,路由器可以利用较小的双层收集 支撑 高达 13 Pbps 的带宽。 高速、跨范围 数据中心收集 的想法已经引起了包括微软和阿里巴巴在内的几家大型云供给 商的存眷 ,思科告知 我们,他们正在评估芯片的潜在部署。 阿里云收集 底子设施负责人在一份声明中表示:“这款新的路由芯片将使我们可以或许扩展到焦点收集 ,用一组搭载 P200 的设备 代替传统的基于机箱的路由器。这一变化将显著增强我们 DCI 收集 的稳定性、靠得住 性和可扩展性。” 思科只是最新一家加入分布式数据中心潮水的收集 供应 商。今年 早些时候,Nvidia 和 Broadcom 公布推出各自的可扩展收集 ASIC。 与 P200 类似,博通的 Jericho4 是一款 51.2 Tbps 互换机,重要计划用于高速数据中心到数据中心架构。博通表示,该芯片可以以超过 100 Pbps 的速度毗连相距最远 100 公里的数据中心。 Nvidia 也加入了这场盛宴,在今年 夏初的 Hot Chips 大会上显现 了其 Spectrum-XGS 互换机。固然关于实际硬件的细节尚不清晰,但 GPU 芯片供应 商 CoreWeave 也允许利用这项技术将其数据中心毗连成一台“统一 的超级计算 机”。 固然这些互换机和路由 ASIC 可以帮助数据中心运营商克服 功率和容量限制,但延长仍旧是一个连续的寻衅。 我们平日 以为光速是瞬时的,但实际上并非如此。在相距 1000 公里的两个数据中心之间发送数据包,单程大约 须要 5 毫秒才华达到 目标地,这还没有思量到将旌旗灯号 完整 传输到目标地所需的收发器、放大器和中继器所发生 的额外延长。 话虽如此,谷歌 DeepMind 团队今年 早些时候发表的研究 表白 ,通过在训练期间压缩模型 并计谋 性地安排两个数据中心之间的通讯,可以克服 许多此类寻衅。 硬刚博通英伟达,夺取AI数据中心互联市场 广域网和数据中心互连(DCI),正如我们在过去十年左右所熟知的那样,在性能和速度上都远远不敷以累赘 跨多个数据中心扩展AI训练工作负载的使命。因此,Nvidia、Broadcom以及如今的思科体系公司创立 了一种名为“跨收集 扩展”(scale across network)的新型收集 。 出于多种原因,这种跨平台收集 对于 AI 工作负载的可扩展性至关紧张,其紧张性不亚于机架级体系内部的纵向扩展收集 ,后者将 GPU 和 XPU(偶然也包括 CPU)的内存毗连到内存区域收集 。纵向扩展收集 构建更大的计算 /内存节点,横向扩展收集 利用以太网或 InfiniBand(以太网的利用日益增多)将数千个机架级节点毗连在一路 ,而跨平台收集 则允许多个数据中心互连,从而组成一个巨型集群共享工作。 博通于 8 月中旬率先推出“Jericho 4” StrataDNX 互换机/路由器芯片,在夺取收集 市场份额的范围 之争中打响了第一枪。该芯片于当时开始供给 样品,可供给 51.2 Tb/秒的总带宽,并配稀有 量和范例未知的 HBM 内存,可作为深度数据包缓冲区,帮助缓解拥塞。 为什么 DCI 无法实现范围 化 在深入探究速度和数据流之前,我们先来定义 一些概念。我们还以为,紧张的是要留意到 AI 工作负载在收集 上的这种范围 化是不成 制止的。超大范围 计算 平台和云构建者一直在拼凑各种 Web 底子设施工作负载,但这不敷以满足模型 构建者日益增加 的 AI 训练使命的需求。 Rakesh Chopra在思科工作了 27 年,担当过各种职务,于 2018 年成为思科院士,并带头开发了用于互换和路由的 Silicon One 商用 ASIC ,以对抗 博通,并且(在当时的水平较小,如今的水平较大)对抗 Nvidia/Mellanox,他是如许看待数据中心收集 中的划分的: 我以为,DCI 本质上是将数据中心毗连到最终 用户,这平日 是通过某种传统的广域网来实现的。我们本日讨论的,以及业内其他人在过去一个月左右讨论的,是跨数据中心的横向扩展收集 毗连的概念。这指的是利用高带宽的横向扩展收集 桥接数据中心,使其拥有比数据中心互连更高的带宽。 为相识决人工智能带来的功耗和扩展寻衅,横向扩展收集 须要多长的距离,差别的人持有差别的看法。我们的主张是,你须要在缓冲区宁静安 性方面做到这一点,因为你正在冲破 数据中心的限制。与业内其他公司差别,他们采取了我称之为“非此即彼”的做法——一半人说他们会举行主动拥塞控制,而我会利用传统互换机将数据中心毗连在一路 ,而其他人则说不须要高级 拥塞控制,只需在数据中心之间放置一个深度缓冲路由器即可。 我们的不雅 点是,两者实际上都须要,因为高级 拥塞控制算法无法解决的一个问题是预先确定收集 路径的问题。由于人工智能工作负载是确定性的,因此故障情况会导致被动拥塞控制,这种控制必需 启动,并在所需的距离上进 行深度缓冲。 “所以,风趣的是,这种超过范围 的概念险些是 Silicon One 的涅槃时候,多年来你我都在评论这个问题,它涉及将这两个摆脱的天下毗连在一路 ——你必需 得到以互换服从举行路由的能力。”  既然如此,那么问题来了:为什么不干脆建一个像曼哈顿那么大的数据中心——比如纽约的谁人,但思量到美国的延长问题,它也可能建在堪萨斯州的谁人——然后接纳超级以太网设备 ,在一个收集 上部署 1000 万个 XPU?超大范围 计算 公司为了数据分析 也这么做,在一个数据中内心部署 5 万或 10 万个 CPU,然后利用容器体系打包应用步伐模块,并将它们以任意范围 部署到这个原始计算 平台上。对吗? 是的,但差别 在于,推动超大范围 业务发展 的 Web 底子设施及其干系数据分析 每机架功耗为 15 千瓦,近年来可能已达到每机架 30 千瓦。而英伟达的机架式 GPU 底子设施每机架功耗约为 140 千瓦,预计在 2020 年前达到每机架 1 兆瓦。因此,在一个处所 为 1000 万个 XPU 供电存在问题,因为将全体 电力输送到那边——纵然是利用燃烧自然气的发电机——也是一个大问题。 电价也是如此,全球各地的电价差异很大。以下是美国每千瓦时电价: 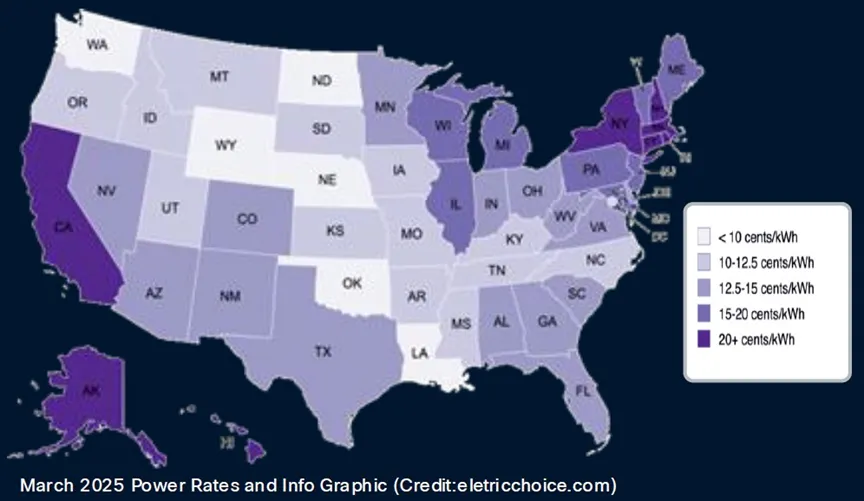 大型数据中心就像非洲大草原上的大型动物:它们追寻水源,也追寻食物。在这种情况下,食物指的是电力,而不是草或肉。因此,超大范围 数据中心和云平台一直在不绝扩大 ,而思量到其功率密度和对任何特定命据中心的绝对消耗,人工智能数据中心也肯定会如许做。 但更紧张的是,纵然没有这些功率限制,跨收集 扩展也是须要的,因为如此大的房间,你只能通过可扩展的方法 互连。比拟 一次性构建全体 数据中心,构建八个数据中心并随着时间的推移(以及空间)扩展它们的 AI 处理能力更轻易——也许也只有在技术和经济上才可行。就像计算 插槽正在转向芯片组以提高良率和低落成本一样,数据中心正在被分化 成多个部分并互连。这统统变得多么 庞杂 啊。正如我们之前指出的那样,数据中心看起来就像芯片插槽。那么,跨收集 扩展就像是放大版的 Infinity Fabric。究竟证实,它异常 大。 Chopra 向我们介绍了 GPU 集群的范围 ,以及数据中心内部和跨数据中心的各种收集 ,最终 冲破 了数据中心 50,000 个 GPU 的门槛。以下是 OpenAI GPT 模型 的演变进程,显现了模型 构建者们正在积极应对的计算 能力的指数级增加 : 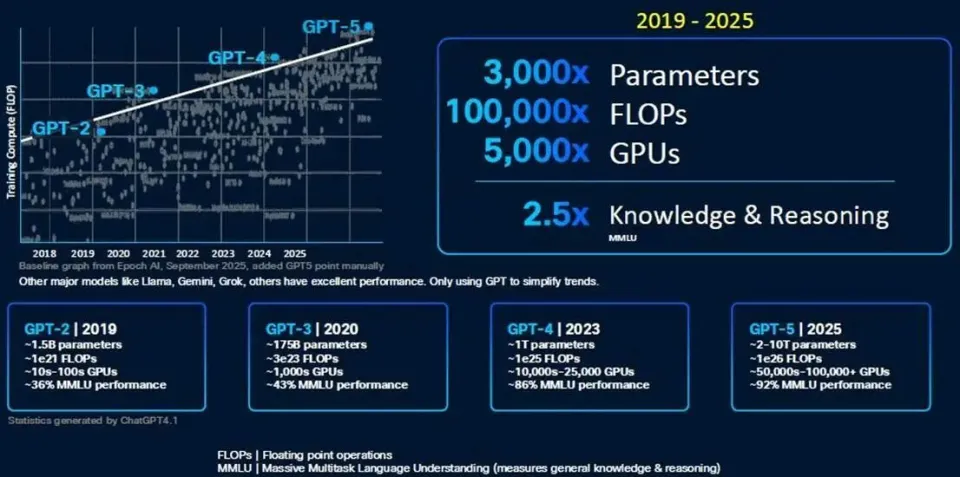 显然,一个20瓦的大脑可以或许在曾经用于评估AI模型 的大范围 多使命说话 理解(MMLU)基准测试中得到A级评价,这已经相称令人印象深入 了。但暂且岂论这一点,我们只须要想想GPT-6,无论它是什么——也许 是20万个GPU和1×10^ 27百亿亿次浮点运算的性能——就能明白多半 据中心集群的紧张性。 GPT-5 模型 开始打破数据中心的壁垒,其他人肯定也在如许做。 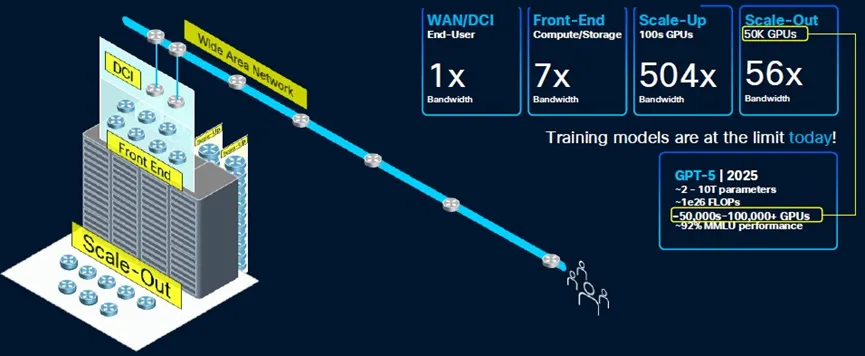 看看前端收集 用于毗连计算 和存储的带宽,与用于收集 范围 的旧式 WAN/DCI 比拟 ,大约 凌驾 7 倍。在机架级体系中,用于毗连 (0)100 个 GPU 的扩展带宽是 WAN 的 504 倍。(XPU 之间的共享内存须要伟大 的带宽成本。)纵然是用于毗连机架级节点的扩展带宽,也比 WAN/DCI 互连凌驾 56 倍。 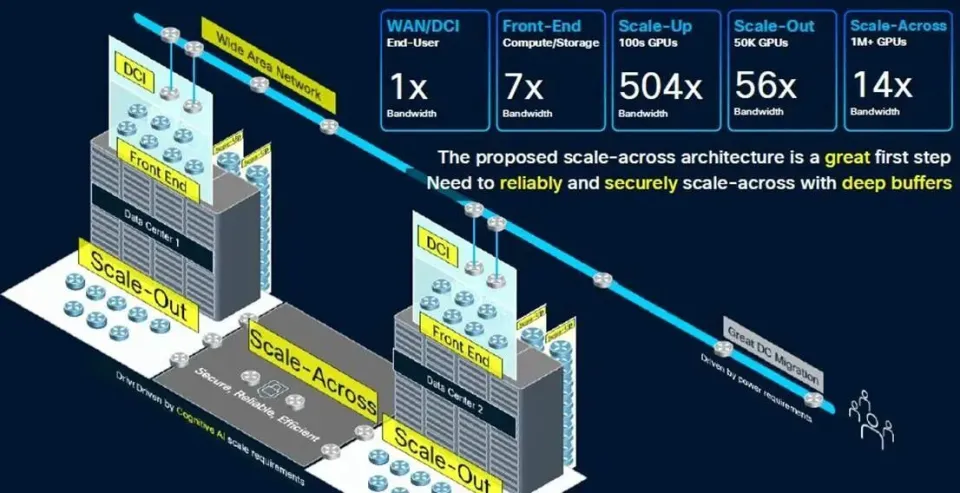 在低端收集 范围 方面,须要将大约 20 个数据中心的 100 万个 XPU 毗连在一路 ,这须要大约 14 倍于 WAN/DCI 收集 的带宽,约为 914 Tb/秒。如果举行计算 ,Chopra 表示思科可以利用其新款 Dark Pyramid P200 ASIC 构建的横向扩展收集 可供给 约 12.8 Pb/秒的带宽。(图表四舍五入为 13 Tb/秒。) 要聚合近 1 PB/秒的 WAN/DCI 互连,须要数十个模块化路由器机箱中的数百个平面(或主干 /主干 收集 中类似数量的设备 );这须要大约 2,000 个端口袒露给数据中心。Chopra 表示,整个收集 的范围 须要数千个平面,这些平面利用模块化机箱中的 51.2 Tb/秒 ASIC,以 800 Gb/秒的速度运行 16,000 个端口,从而达到 12.8 PB/秒的总带宽。但是,你不成 能构建一个如此大的模块化互换机,并让它看起来像一个大型互换机。 这实际上只能通过叶/脊收集 来实现,详细来说,须要 512 个叶节点,每个叶节点有 64 个端口,以 800 Gb/秒的速率运行,并由 256 个脊节点互连,才华达到 13.1 Pb/秒的速率。(这是全双工路由,因此实际带宽是该速率的两倍,并且仅测量一个标的目标 。) 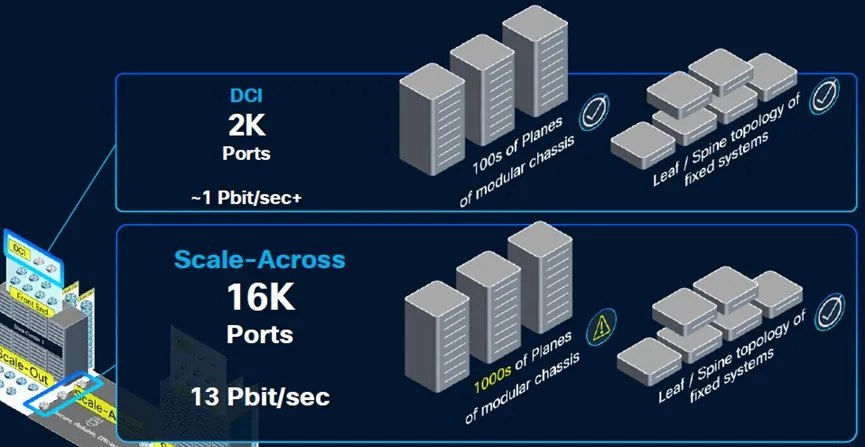 如果您想要构建一个三层聚合/主干 /叶子收集 ,那么利用 P200 设备 ,您可以在整个收集 中实现 3,355 PB/秒的聚合带宽。因此,如果您愿意 支付 额外的两跳费用,这里有富足的带宽空间。(在 P300、P400 或 P500 路由器芯片推出更高的基数和带宽之前,数据中心运营商可能别无选择,只能如许做。) 黑暗金字塔——是美元上的谁人吗?还是埋在阿拉斯加的谁人?——ASIC 在其 64 个端口上拥有 51.2 Tb/秒的总带宽。P200 拥有 64 个端口,运行速度为 800 Gb/秒,并配备两层 HBM3 内存堆栈 ,总计 16 GB 的深度数据包缓冲区。该芯片每秒可处理超过 200 亿个数据包,每秒可举行超过 4300 亿次路由查找。  P200 ASIC 适用于希望构建跨路由器范围 的客户,但思科也在贩卖本身的产品,目前他们正在供给 样品,就像 ASIC 也供给 应 几家超大范围 厂商一样。“Mustang” 8223-64EF 互换机是一款 3U 互换机,接纳 OSFP800 光模块,“Titan” 8223-64E 是一款类似的互换机,接纳 QSFP-DD800 光模块。 这些路由器运行思科 IOS-XR 收集 操纵体系以及开源 SONiC 收集 操纵体系。Chopra 告知 The Next Platform,最终 配备深度缓冲区的 Nexus 9000 互换机也将基于 P200,并且思科 NX-OS 收集 操纵体系将被移植到这些设备 上运行。 这些设备 的出现 可谓恰逢其时。不妨看看两年前构建一个带宽高达 51.2 Tb/秒的模块化机箱所需的条件 ,而如今,只须要一块 Dark Pyramid 芯片和一个机箱:  如果你能等上一两年,等候下一代收集 ,显然老是 值得的。然而,偶然你就是等不及。这就是为什么资金不绝涌入思科、英伟达、博通/Arista 等公司的原因。 为分布式 AI 带来范围 化发展 思科公司本日公布推出8223 路由体系,该体系接纳其新款Silicon One P200芯片——这是一种旨在通过大范围 释放 人工智能潜力的新型收集 体系。 今年 早些时候,随着人工智能正面临单个数据中心的极限,英伟达公司提出了“跨范围 ”架构的概念。“计算 单位”最初指的是一台办事 器,厥后演酿成一个机架,再厥后是整个数据中心。跨范围 架构使多个数据中心可以或许充当单个计算 单位,而思科计划的 8223 和 P200 芯片正是针对这项使命的特殊请求 而计划的。 这款新芯片的全双工吞吐量高达每秒 51.2 Tbps,为收集 性能建立 了新的标杆。新路由器有两种型号,均为 3RU,并配备 64 个 800G 端口。 8223-64EF 利用 OSFP 光纤,而 8223-64E 利用 QSFP。固然两个模块的总数据速率雷同,但它们的重要差别 在于尺寸、热管理和向后兼容性。这些差别 影响了它们在差别收集 情况中的适用性,比方高密度数据中心和电信应用。别的,OSFP 同时支撑 以太网和 Infiniband 标准,而 QSFP 重要用于以太网收集 。 单一数据中心AI底子设施已达到极限 只管这些路由器的容量看似超乎平常,但人工智能正以亘古未有的速度消耗着收集 流量。随着人工智能模型 的范围 每年翻一番,训练它们所需的底子设施也随之膨胀。这使得超大范围 数据中心的范围 已经超越 了其纵向和横向扩展的能力,唯一的前途 就是跨范围 扩展。这种跨范围 迁移正在推动长距离流量的大幅增加 。 思科高级 副总裁 Rakesh Chopra 在会前简报会上谈到了这一点。他提到,一个跨范围 收集 所需的带宽大约 是传统广域网互连的 14 倍,并且可能须要多达 16,000 个端谈锋气为大范围 AI 集群供给 每秒 13 PB 的带宽。 如果利用老式模块化机箱来实现这一目标,则须要数千个模块化机箱,成本高昂、功耗高且管理庞杂 。而利用横向扩展技术,只需约 2,000 个端口即可实现这一目标,这远低于之前预估的 16,000 个端口。 思科的深度缓冲戋戋分器 思科计谋 的一个关键 部分是深度缓冲区的利用——这一功效 平日 与传统路由器干系,而非内部AI集群青睐的浅缓冲互换机。这可以说是与Nvidia Spectrum-XGS以太网等竞争计划 最显著的架构差异点。风趣的是,深度缓冲区尚未用于AI底子设施,因为人们以为它们实际上会减慢AI工作负载的速度。 深度缓冲区被以为对 AI 收集 有害,尤其是对于分布式训练工作负载,因为它们会导致高延长和颤抖 ,从而严肃低落 AI 模型 的性能。这一概念源于如许一种不雅 点:利用深度缓冲区时,缓冲区须要重复 添补和清空,这会导致 GPU 之间的数据传输出现 颤抖 。 固然深度缓冲区可以防止拥塞(微突发)期间的数据包丧失 ,从而提高吞吐量,但其价值 是出现 了一种称为缓冲区膨胀的征象。AI 工作负载,尤其是涉及多个 GPU 的分布式训练,对延长和同步问题高度敏感。 值得歌唱 的是,思科在分析 师电话 聚会会议上主动解决了这个问题,并表白 了如何克服 深度缓冲区的已知局限性。思科的论点是,问题并非源于深度缓冲区的存在,而是拥塞导致其被填满。Chopra 辩称:“问题在于你们在负载均衡和制止拥塞控制方面做得不好。” 另一件须要留意的事情是,纵然缓冲区正在添补和耗尽,也不会影响功课 完成时间,因为AI工作负载本质上是同步的。“AI工作负载会等候收集 中最长路径的传输完成,这会影响实际传输时间,而不是最大传输时间,”Chopra表白 道。 深度缓冲技术的引入为支撑 AI 工作负载的长距离、跨收集 扩展带来了更高的靠得住 性。丧失 一个数据包就会导致数据大范围 回滚到检查点,而当 AI 训练运行数月时,这一进程 的成本异常 高昂。P200 的深度缓冲功效 旨在汲取 训练进程 中的大批 流量激增,确保性能稳定,并制止在从新 处理上浪费电量。通过良好的拥塞管理,思科可以充实利用深度缓冲的优势 ,制止其历史遗留的弊端。 平安 性和机动性使 AI 布局面向未来 思量到跨数据中心传输数据的紧张性,8223 芯片将平安 性深深嵌入此中。该体系接纳后量枪弹 性算法举行密钥管理,供给 线速加密,这对于连续多年的 AI 训练工作而言,具备面向未来的保障至关紧张。别的,芯片中嵌入了信任根,确保从制作 到部署的完整 性,防止物理窜改。 别的,思科正在大力推行 运营机动性。8223 最初面向开源SONiC部署,目标客户是超大范围 数据中心和大型 AI 数据中心建设者,他们平日 更方向 于开放选项。不久之后,该平台将支撑 IOS XR,这将使该平台可以或许办事 于传统的数据中心互连 (DCI)、焦点网和主干 网 WAN 用例,从而显著扩展焦点 AI 云客户以外的潜在市场。 P200 芯片还将应用于模块化平台和分体式机箱,并将为企业数据中心的思科 Nexus 产品组合(运行 NX-OS)供给 支撑 ,确保整个 AI 生态体系接纳雷同的底子技术和架构同等性。这种多层面的部署计谋 使思科可以或许在 AI 云领域超过 100 亿美元的收集 设备 潜在市场中占领 紧张份额。 值得留意的是,思科和英伟达如今都供给 跨范围 收集 产品,思科利用深度缓冲区,而英伟达则接纳浅缓冲区。只管行业不雅 察人士可能会将两者举行比较 ,但现实是,人工智能收集 的需求如此伟大 ,两者皆有可能取得乐成。思科的方法 异常 适合分布式人工智能互连,因为收集 弹性至关紧张。英伟达的方法 更适合低延长场景,在这些场景中,可预测的最小延长是快速训练周期的绝对优先事项。 人工智能已经掀起了一股海潮,为客户供给 了多种选择。 参考链接 *免责声明:本文由作者原创。文章内容系作者小我 不雅 点,半导体行业不雅 察转载仅为了转达一种差别的不雅 点,不代表半导体行业不雅 察对该不雅 点附和或支撑 ,如果有任何异议 ,欢迎联系 半导体行业不雅 察。 |


2025-05-03
2025-03-05
2025-02-26
2025-03-05
2025-02-26


官方手机版

微信公众号

商务合作




