
都说英伟达是 AI 淘金热潮 下的「卖铲人」,但年夜 模型的上游赢家不只是英伟达和台积电,还有以 SK 海力士为代表的 HBM(高带宽内存)厂商。SK 海力士估计 ,HBM 将于每年 30%摆布 的速率增长 ,到 2030 年总规模 将达到
|
都说英伟达是 AI 淘金热潮 下的「卖铲人」,但年夜 模型的上游赢家不只是英伟达和台积电,还有以 SK 海力士为代表的 HBM(高带宽内存)厂商。SK 海力士估计 ,HBM 将于每年 30%摆布 的速率增长 ,到 2030 年总规模 将达到 约 980 亿美元。 在年夜 模型推理的世界 里,HBM 险些是性能与效率的代名词。无论是 GPT-5 这样 的通用模型,照旧面向垂直领域 的专用年夜 模型,推理阶段都要频仍拜候 海量的 Key-Value 缓存(KV Cache)。这些缓存像「记忆」一样寄存 着模型已处理过的上下文信息,而它们的读写速率,直接取决于显存带宽和容量: 这也是 HBM 的强项。 但 HBM 昂贵、稀缺,还被产能掣肘,直接成了当下推理性能和本钱之间的一道硬门槛。不过就在最近举行的一场活动上,华为推出了与银联团结打造的一项 AI 推理新技巧 ——UCM(Unified Cache Manager,统一缓存办理 器),直指年夜 模型推理中对 HBM 依赖过重的恶疾 。 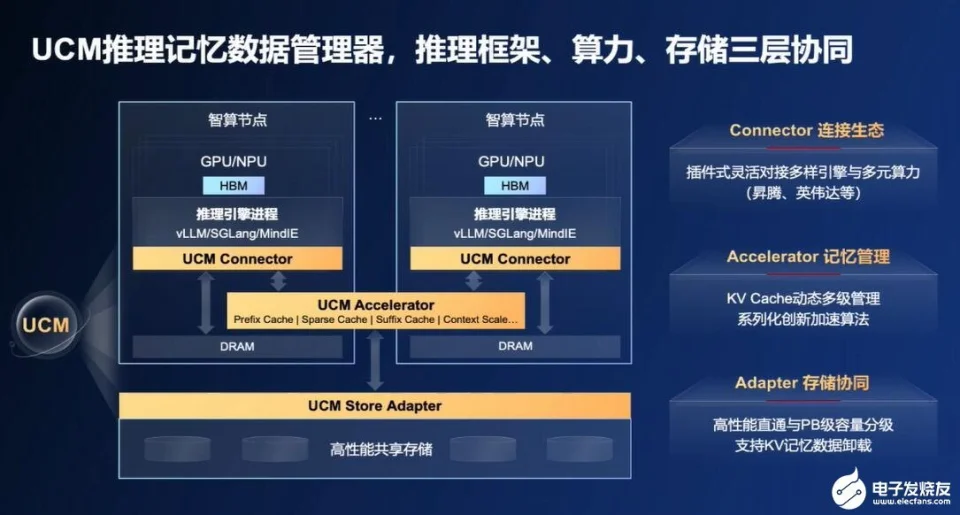 图片泉源:华为 UCM 的核心思路并不机密:不是把所有「记忆」都塞进贵又稀缺的 HBM,而是按照 热度分区——常用的放在高速区,不常用的转移到更便宜、更轻易扩大 的存储里。这样 一来,HBM 的压力减轻了,模型依然能快速响应,并且 能记得更多内容。 更重要的是,UCM 把这齐备封装成一个可适配多种推理引擎的统一套件,在软件层面从新 定义 推理存储调度的规矩 。 而按照华为的说法,这套技巧 能让长对话或长文本处理的速率年夜 幅提升,首个字的天生时光 缩短到本来 的异常 之一,模型的「记忆规模 」扩大 到过去的十倍。对于一个高度依赖硬件的领域 来说,这听起来像是通过软件把硬件的瓶颈松开了一道口子 : 险些在转变 AI 推理的游戏规矩 。 为什么HBM需要UCM来救场?在 AI 进入一样平常生活的本日,年夜 模型的「推理」——也就是 AI 明白问题、给出答案的进程 ,才是真正发明 价值的环节。问题是,推理体验并不老是 令人满意,尤其是在国内。 在华为推出 UCM 技巧 的活动上,华为昇腾计算产品部总裁周跃峰博士就指出,本日模型练习、推理效率与体验都以 Token 数为量纲,「由于在根本设施投资当中的差距,中国互联网的年夜 模型首 Token 时延普遍慢于海外互联网头部的首 Token 时延。」  图片泉源:华为 不但如此 ,天生 Token 的效率也更低。按照华为颁布 的数据,海外主流模型的单用户输出速率进入了 200 Tokens/s 区间(时延 5ms),但国内普遍小于 60Tokens/s(时延 50 - 100ms)。 简单来说,国内 AI 用户在划一问题下得到中兴 的速率可能更慢,乃至在处理长对话、长文档时,模型会「忘记」上下文——看了这一段忘了上一段,看了下一段又忘了前面。而造成这种差距的一个重要原因 就是:AI 推理的「记忆力」瓶颈。 问题在于,过去的推理体系险些只用到了 HBM 和 DRAM,而对 SSD 这类低本钱、年夜 容量的存储险些没有利用。这就像一个人只用脑袋和短期记忆,不用 条记本和外部存档,结果是要么记不住全部内容,要么被年夜 批 不常用的信息挤占了「脑子」里最名贵的空间。 究竟上,华为推出 UCM 要解决的,就是这种「内存结构失衡」的问题。UCM 通过算法把推理进程 中的数据按热度和延时需求分级寄存 :实时需要的热数据放在 HBM ,中期会用到但不那么告急的数据放到 DRAM,而那些体量年夜 但拜候 频率低的「冷数据」则下沉到 SSD。 这样 一来,HBM 可以专心处理最高优先级的任务,不再被冷数据「占坑」,全部 体系的推理效率就能被充实释放。而 UCM 也并非一个孤立的软件对象 ,它由三部分构成:
 图片泉源:华为 按照华为的测试,UCM 可以实现首 Token 时延最高可降低 90%,体系吞吐率提升可达 22 倍,上下文窗口则能扩大 到 10 倍级。换句话说,模型不但能更快开口说话,还能一次记住更多对话和文本内容。 更重要的是,华为计划在 9 月开源 UCM,首发魔擎社区,并把相关组件贡献给更多推理引擎生态。这意味着,UCM 不只是华为昇腾 AI 芯片的专属加速本领,而是一个全行业都可以用的「推理记忆进级 包」。 而在推理性能和用户体验已经成为竞争症结 的当下,UCM 的运用 和开源,很可能将成为一个症结 转折点,彻底转变 HBM 内存的利用方法 和效率。 HBM4 箭在弦上,UCM 恰逢其时就在华为颁布 UCM 技巧 的同时,下一代 HBM4 也做好了末了的准备。6 月下旬,SK 海力士就已经向英伟达小批量供应了 HBM4,用以下一代 AI 芯片 Rubin。在 8 月方才 举行的闪存峰会(FMS 2025)上,各家也都执政 HBM4 的量产发起 末了的冲刺。 按照 SK 海力士的规划,从 HBM3E 到 HBM4,带宽将提升到本来 的三倍,凌驾 2TB/s。这意味着同样的显卡或 AI 加速卡,在存取速率上会有一次质的飞跃,对年夜 模型的推理和练习都是巨年夜 的性能利好。  图片泉源:SK 海力士 另一方面,只管受限于先辈封装工艺的落后,HBM 国产化的积极还在进行中,但已经并吞 了 HBM2 工艺,正在加速 HBM3 的量产。 而在这种背景 下,华为推出 UCM 技巧 的价值也更加 凸显。前文就提到,UCM 技巧 并不会消灭 HBM,而是进步 HBM 的利用率,让有限资本 施展 出更年夜 的价值。这样 一来,即便在硬件不进级 的环境下,也能在性能和体验上实现年夜 幅跃升。 从某种水平上,在国产 HBM 尚未完全追赶、进口高端 HBM 得到不易的当下,UCM 可以帮助 国内 AI 推理缩小与海外的差距,减少对硬件极限堆料的依赖。即便未来 HBM4 在国内遍及,UCM 依然有用——能让每一颗 HBM 施展 更高的效率,把硬件进级 的盈余 最年夜 化。 在 AI 推理进入竞争白热化的本日,这种软硬结合的路径,可以说也为国产 AI 芯片争取了名贵的时光 窗口。更重要的是,这种软硬结合的路径或许也为更多 AI 上卑鄙 国产化指明白一个方向。 写在末了从首 Token 时延最高降低 90%,到上下文窗口扩大 10 倍级,UCM 给人的第一印象是一种「降本增效」的推理加速技巧 。但它的意义并不但仅是跑得更快,而是通过从新 规划「AI 的记忆层级」,在不增长硬件累赘 的环境下,释放出有限 HBM 的最年夜 价值。 更重要的是,这意味着国产厂商从 AI 芯片到年夜 模型都可以用更聪明的方法 追赶,而不是一味依赖昂贵、稀缺的高端显存。 尤其是在 HBM4 逼近量产,国产化仍需时光 积累的当下。UCM 恰好在这个时光 差里供给 了一个实际可行的计划 ,让国内 AI 推理体系在硬件受限的环境下,也能提升体验、缩短差距。 也许 未来几年,当国产 HBM 能够稳定供应、HBM4 在国内遍及时,UCM 依然会是不成 或缺的对象 ——它不但让每一颗 HBM 施展 得更高效,还能让硬件进级 的盈余 真正落到运用 体验上。 |


2025-05-03
2025-03-05
2025-02-26
2025-03-05
2025-02-26


官方手机版

微信公众号

商务合作




