
(文/视察 者网 吕栋 编辑 /张广凯) 全部人都没有预感 到,华为会忽然亮出未来几年的“芯片底牌”。 9月18日上午,在华为全毗连年夜 会2025上,华为轮值董事长徐直军一口气公布 了多颗芯片,包括用于AI计算 的
|
 (文/视察 者网 吕栋 编辑 /张广凯) 全部人都没有预感 到,华为会忽然亮出未来几年的“芯片底牌”。 9月18日上午,在华为全毗连年夜 会2025上,华为轮值董事长徐直军一口气公布 了多颗芯片,包括用于AI计算 的昇腾950系列、昇腾960系列和昇腾970系列,用于通用计算 的鲲鹏950处理器和鲲鹏960处理器,以及由这些芯片组成 的“举世最强超节点”和“举世最强算力集群”。 要知道,华为上一次公开发布昇腾和鲲鹏芯片,照旧2019年。自那以来,在美国多轮制裁下,无论是麒麟,照旧昇腾和鲲鹏均遭重击。即便年夜 家都知道近来两时间 为芯片已逐步回归,但依然比较神秘,包括麒麟、鲲鹏和昇腾这些芯片未来如何 迭代的,外界都不得而知。 “下面我别离 先容将近推出的和已筹划 的4颗昇腾芯片”、“我们自研了两种HBM”“鲲鹏处理器主要环绕 支撑 超节点,更多核、更高性能等方向连续演进”......因此当徐直军直入主题直接先容华为“未来的芯片路标”时,在场世人 无不感到吃惊,思绪也被拉回几年前。
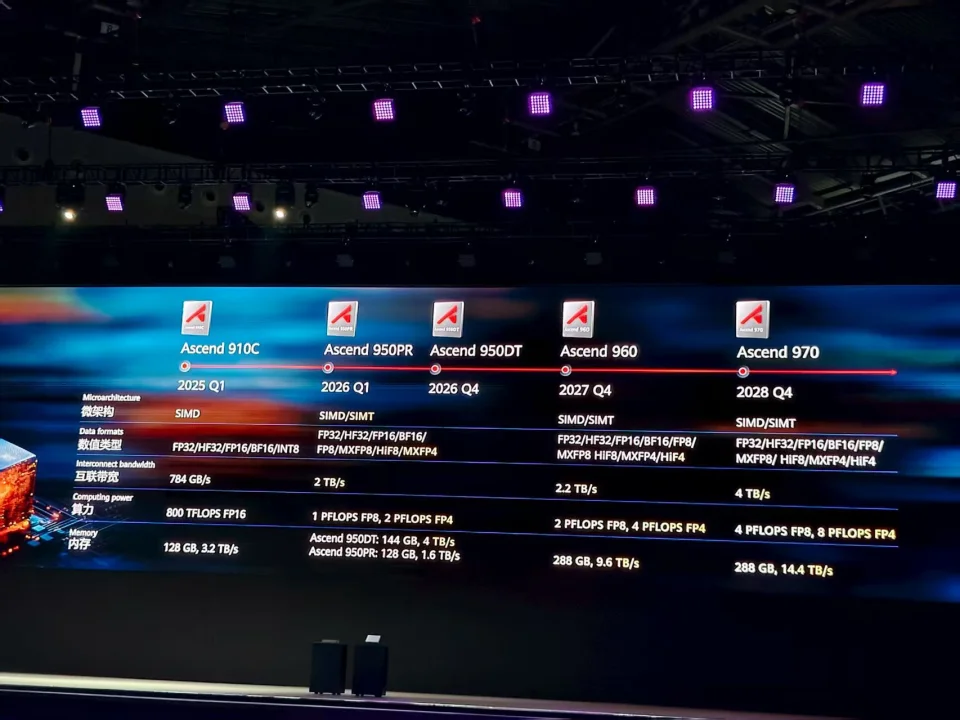 图源:视察 者网 选在这个时光 点“秀肌肉”,华为除了要展现 “打不逝世 ”的韧性,更想在AI时代给中国人工智能的发展托底,给国内产业伙伴吃下更多“放心丸”。“我很确定地告诉年夜 家,昇腾芯片将连续演进,为中国以致世界的AI算力修建 结实基础 。”徐直军在会上如是说道。 只管DeepSeek开创的模式可以年夜 幅淘汰算力成本,但徐直军以为,要走向通用人工智能、走向物理AI,算力将继续是人工智能的关键,更是中国人工智能的关键。 他在会上起首先容了昇腾950系列芯片。与前一代比,昇腾950系列的提高 有几个方面,包括支撑 FP8/MXFP8/MXFP4等低数值精度数据格式,算力可到达1P和2P,提拔练习服从和推理吞吐,并特别支撑 华为自研的HiF8,在坚持 FP8的高效的同时,精度异常 靠近FP16。 不同的处所 在于,华为连合推理不同阶段对算力、内存和访存带宽等不同需求,自研了两种低成本HBM(高带宽内存),不同的HBM与昇腾950裸芯片合封,别离 组成 昇腾950PR:面向Prefill和推荐场景,以及昇腾950DT:面向Decode和练习场景。两颗芯片都将在明年上市。
图源:视察 者网 徐直军还公布 了筹划 中的两颗AI芯片。 昇腾960性能规格将比昇腾950翻倍,支撑 华为自研的HiF4数据格式,能进一步提拔推理吞吐,而且比业界FP4筹划 的推理精度更优,筹划在2027年四季度推出;昇腾970的规格还在品评辩说 中,比拟 昇腾960,昇腾970的FP4算力、FP8算力、互联带宽将全面翻倍,内存拜候 带宽至少增加1.5倍,筹划在2028年四季度推出。
 图源:视察 者网 我们都知道,固然国产AI芯片因为 制造工艺标题,单卡算力处于掉队状态,但AI对算力的庞年夜 需求,让单芯片脚色逐步弱化,集群算力成为局势所趋。因此本年3月,华为综合在光通讯、收集 、供电等多方面的技术,把384颗昇腾芯片经过过程 高速互联总线连在一起,推出了举世最年夜 的超节点,性能指标高出了英伟达NVL72体系,它的上风是让计算 和通讯高速并行,充分提拔算力使用率,已摆设超300套。 但华为并没有停下脚步,这次重磅公布了未来的超节点筹划 。 起首,是筹划2026年四季度上市的Atlas 950超节点,它基于8192颗昇腾950DT芯片打造,满配包括由128个计算 柜、32个互联柜,共计160个机柜组成 ,占地面积1000平方米摆布 ,柜间接纳全光互联,总算力年夜 幅度提拔,其中FP8算力到达8E FLOPS,FP4算力到达16E FLOPS,互联带宽到达16PB/s,这个数字意味着,Atlas 950一个产品的总互联带宽,已经高出今天 举世互联网峰值带宽的10倍。 “Atlas 950超节点,至少在未来多年都将坚持 是举世最强算力的超节点,而且在各项主要本事上都远超业界主要产品。其中,比拟 英伟达同样将在明年下半年上市的NVL144,Atlas 950超节点卡的范围 是其56.8倍,总算力是其6.7倍,内存容量是其15倍,到达1152TB;互联带宽是其62倍,到达16.3PB/s。即使是与英伟达筹划2027年上市的 NVL576比拟 ,Atlas 950超节点在各方面依然是领先的。”徐直军说道。
 图源:视察 者网 这仍旧不敷。 面向更长远,华为筹划在2027年四季度推出Atlas 960超节点,它基于15488颗昇腾960芯片组成 ,包括176个计算 柜,44个互联柜,共220个机柜,占地面积约2200平方米,其总算力、内存容量、互联带宽在Atlas 950基础上再翻倍。其中,FP8总算力将到达30E FLOPS,而FP4总算力将到达60 EFLOPS;内存容量到达4460TB,互联带宽到达34PB/s。 不光是AI芯片迭代,华为还同时布局通用计算 CPU。 徐直军泄漏 ,华为将在明年一季度推出鲲鹏950处理器,包括两个版本,别离 是96核/192线程和192核/384线程,成为鲲鹏首颗实现秘密计算 的数据中心处理器。然后在2028年一季度,推出鲲鹏960处理器,高性能版本96核/192线程,高密版本不少于256核/512线程。 紧接着,他公布了基于鲲鹏950的TaiShan 950超节点,是举世首个通用计算 超节点,明年一季度上市,最年夜 支撑 16节点,32个处理器,最年夜 内存48TB,支撑 内存、SSD、DPU池化。
 图源:视察 者网 “当前年夜 型机、小型机更换的核心挑衅 是数据库散布 式改造,而基于TaiShan 950超节点打造的GaussDB多写架构,无需改造,但性能提拔2.9倍,最终 可平滑 替代年夜 型机、小型机上的传统数据库。TaiShan 950加上散布 式GaussDB将成为各类年夜 型机、小型机的闭幕者,彻底代替各类 应用处 景的年夜 型机和小型机以及Oracle的Exadata数据库办事 器。”徐直军表现。 看到超节点的体系性上风后,华为还筹划推出TaiShan 950和Atlas 950肴杂超节点。这样一方面可以经过过程 超年夜 带宽、超低时延互联以及超年夜 内存,组成 超年夜 共享内存池,支撑 PB级推荐体系嵌入表;另一方面,肴杂超节点的超年夜 AI算力,可以或许支撑 超低时延推理和特性检索。 然则 这样也会带来伟年夜 的挑衅 。比如在长距离毗连和靠得住 性方面,当前的电互联技术在高速时联接距离短,而光互联更容易出故障。同时,当前跨柜卡间互联带宽低,和超节点的需求差距达5倍;跨柜的卡间时延年夜 ,当前互联技术最好只能做到3微秒摆布 ,和Atlas 950/960设计需求仍旧有24%的差距,其时延已经低至2~3个微秒时,0.1微秒的提拔挑衅 都很年夜 。
 图源:视察 者网 徐直军泄漏 ,为了达成Atlas 950/960超节点对互联的技术请求 ,为了实现万卡超节点还能是一台计算 机,华为开创了超节点架构并开创了新型的互联协议 ,可以或许支撑万卡级超节点架构。 在技术上,万卡级超节点架构具备6年夜 特性,别离 是总线级互联、同等协同、全量池化、协议 归一、年夜 范围 组网、高可用性。这个面向超节点的新型互联协议 ,被命名为“灵衢”,意味着类似九省通衢,实现年夜 范围 算力的联通,英文名称:UB(UnifiedBus)。 徐直军表现,为了更普遍 地促进互联技术发展和产业提高 ,华为决议 开放灵衢2.0技术规范,接待产业界伙伴基于灵衢研发相关产品和部件,共建灵衢开放生态,“灵衢既为超节点而生,是面向超节点的互联协议 ,也是构建算力集群产品最优的互联技术。” 他随后公布了两个年夜 范围 计算 集群。 起首是Atlas 950 SuperCluster集群,由64个Atlas 950超节点互联组成 ,把1万多机柜中的52万多片昇腾950DT组成 为一个整体,FP8总算力可达524 EFLOPS。比拟 当宿世界上最年夜 的集群 xAI Colossus,范围 是其2.5倍,算力是其1.3倍,“是当之无愧的全世界最强算力集群”。与此同时,2027年四季度,华为还筹划基于Atlas 960超节点,推出Atlas 960 SuperCluster,集群范围 进一步提拔到百万卡级,FP8总算力到达2 ZFLOPS,FP4总算力到达4 ZFLOPS。
 图源:视察 者网 但不成 否认的是,AI算力的释放 不仅磨练硬件性能,也对配套软件和开发对象 提出了更高请求 。就像英伟达之所以力气强横,不仅因为它的GPU性能强,也得益于CUDA生态成熟。 华为固然有自己的昇腾芯片,但也必要CANN来发挥 “CUDA”的脚色。与CANN配套的是华为自研深度学习框架MindSpore,其作用类似于PyTorch,这些对象 配合 组成 了华为原生的AI软硬件筹划 ,以对标以英伟达为中心的PyTorch+CUDA筹划 。 坦白来讲,与发展了18年的CUDA生态比拟 ,刚起步六七年的CANN,易用性和生态丰硕 度仍存在差距,而且任重道远。客岁9月有外媒报道,为了让客户顺应新生态,华为效仿英伟达最初推广CUDA的策略,向百度、科年夜 讯飞和腾讯调派了工程团队,帮助他们在CANN情况中重现和优化现有的基于CUDA的练习代码。 面临强年夜 的CUDA生态,坚持开源构建生态或许是华为的最优选择。 徐直军在会上重申了华为的开源策略和门路:一、华为坚持昇腾硬件变现;二、CANN编译器和假造指令集接口开放,其它软件全开源,CANN基于Ascend 910B/C的开源开放将于2025年12月31日前完成,未来开源开放与产品上市同步;三、Mind系列应用使能套件及对象 链全面开源,并于2025年12月31日前完成;四、openPangu基础年夜 模型全面开源。
 图源:视察 者网 从徐直军的演讲不难看出,华为未来的计算 产业战略是,硬件将基于现有芯片工艺迭代昇腾和鲲鹏,同时以体系补单点,用超节点补足单卡瓶颈;软件上,华为将坚持开摊开 源,经过过程 开放灵衢2.0技术规范,构建CANN和MindSpore等开源生态,解决 美国的算力卡脖子标题。 以下是徐直军演讲全文: 女士 们、先生们,各位老朋友、新朋友,年夜 家上午好! 接待来参加2025时间 为全联接年夜 会,时隔一年,很高兴再次与年夜 家相聚在上海。我想年夜 家都能感触感染 到,已往的一年对全部AI从业者、存眷 者来讲是记忆深入 的一年,DeepSeek横空降生 ,让天下人平易近 过了一个快活 的AI年,也让全部年夜 模型练习者开启了不知多少个不眠之夜,调剂 练习方式,复现DeepSeek结果,当然也给我们带来了伟年夜 打击。从春节开端 ,到本年4月30日,经过多团队的协同作战,终于使Ascend 910B/910C的推理本事达成了客户的基本需求。 在进入今天 的详细分享之前,请允许我回顾一下客岁的HC,我讲到了如下几点: 第一、智能化的可连续,起首是算力的可连续; 第二、中国半导体制造工艺将在相当长时光 处于掉队状态; 第三、可连续的算力只能基于现实可获得的芯片制造工艺; 第四、人工智能成为主导性算力需求,促使计算 体系正在产生 结构性变化; 第五、开创计算 架构,打造“超节点+集群”算力解决 筹划 连续满意算力需求。 但第五点没有睁开讲,原来想讲,但我的团队不同意 。今天 ,我想使用此机会,来把我客岁HC没有完成的任务完成,也算是答卷。我今天 禀享的主题是:“以开创的超节点互联技术,引领AI基础办法新范式”,也是复兴客岁HC提到的第五点:如何 开创计算 架构,打造 “超节点+集群”算力解决 筹划 来连续满意算力需求。 在睁开今天 主题前,回到DeepSeek对产业界、对华为的打击,DeepSeek开源后,我们的客户对华为的昇腾发展指出了许多标题,也充满了等待,并一直在给我们不停地提发起。为此,经过内部的充分品评辩说 并达成共识,我们于2025年8月5日在北京专门举行了昇腾产业峰会,我代表华为给出了回应,在座的有的参加了,有的年夜 概没有参加。今天 ,我也使用此机会就主要的决议 给年夜 家报告一下。主要有四点: 一、华为坚持昇腾硬件变现; 二、CANN编译器和假造指令集接口开放,其它软件全开源,CANN基于Ascend 910B/C的开源开放将于2025年12月31日前完成,未来开源开放与产品上市同步; 三、Mind系列应用使能套件及对象 链全面开源,并于2025年12月31日前完成; 四、openPangu基础年夜 模型全面开源。 接下来回到今天 的主题。 只管DeepSeek开创的模式可以年夜 幅淘汰算力需求,但要走向AGI、要走向物理AI,我们以为,算力,已往是,未来也将继续是人工智能的关键,更是中国人工智能的关键。 算力的基础是芯片,昇腾芯片是华为AI算力战略的基础。自2018年发布Ascend 310芯片,2019年发布Ascend 910芯片,到2025年,Ascend 910C芯片跟着 Atlas 900超节点范围 摆设,为年夜 家所熟悉。在已往几年,客户和伙伴们对昇腾芯片有许多诉求,对昇腾芯片也有许多等待。面向未来,华为的芯片路标是如何 筹划 的?想必是年夜 家普遍 关心的话题,年夜 概也是最关心的内容。 因此,今天 ,我就直入主题来先容昇腾芯片及其路标。我很确定地告诉年夜 家,昇腾芯片将连续演进,为中国以致世界的AI算力修建 结实基础 。 未来3年,至2028年,我们在开发和筹划 了三个系列,别离 是Ascend 950系列,包括两颗芯片:Ascend 950PR和Ascend 950DT,以及Ascend 960、Ascend 970系列,更多详细芯片还在筹划 中。下面我别离 先容将近推出的和已筹划 的4颗昇腾芯片。 我们正在开发、且即将推出的芯片叫Ascend 950系列。我起首先容一下Ascend 950系列的芯片架构,Ascend 950 PR和Ascend 950 DT共用了Ascend 950 Die。与前一代昇腾芯片比拟 ,Ascend 950 在以下几个方面实现了基本 性提拔。 第一,新增支撑 业界尺度FP8/MXFP8/MXFP4等低数值精度数据格式,算力别离 到达1P和2P,提拔练习服从和推理吞吐。并特别支撑 华为自研的HiF8,在坚持 FP8的高效的同时,精度异常 靠近FP16。 第二,年夜 幅度提拔了向量算力。这主要经过过程 三个方面实现:其一,提拔向量算力占比;其二,接纳立异 的新同构设计,即支撑 SIMD/SIMT 双编程模型,SIMD可以或许像流水线一样处理“年夜 块”向量,而SIMT便于机动处理“碎片化”数据;其三,把内存拜候 颗粒度从512字节淘汰到128字节,内存拜候 更精细,从而更好地支撑 了离散且不连续的内存拜候 。 第三,互联带宽比拟 Ascend 910C提拔了2.5倍,到达2TB/s。 第四,连合推理不同阶段对于算力、内存、访存带宽及推荐、练习的需求不同,我们自研了两种HBM,别离 是:HiBL 1.0和HiZQ 2.0。不同的自研HBM与Ascend 950 Die合封,别离 组成 芯片Ascend 950PR:面向Prefill和推荐场景,以及Ascend 950DT:面向Decode和练习场景。下面别离 先容。 起首是我们的第一颗芯片,Ascend 950PR,主要面向推理Prefill阶段和推荐营业 场景。起首,我们发现,跟着 Agent的快速发展,输入高低 文越来越长,首Token输出阶段占用计算 资本 越来越多。其次是在电子商务、内容平台、社交媒体等营业 应用中,请求 推荐算法具有更高的正确度和更低的时延,对计算 本事的需求也越来越年夜 。推理Prefill阶段和推荐算法都是计算 麋集型,对计算 并行的本事请求 高,但对内存拜候 带宽的需求相对低。通太过级内存解决 筹划 ,推理Prefill阶段和推荐算法对本地内存容量的需求相对也不高。Ascend 950PR 接纳了华为自研的低成本HBM,HiBL 1.0,比拟 高性能、高代价的HBM3e/4e,可以或许年夜 年夜 低落推理Prefill阶段和推荐营业 的投资。 这颗芯片将在2026年一季度推出,起首支撑 的产品形态是标卡和超节点办事 器。 接下来这一颗是Ascend 950DT,比拟 Ascend 950PR,它更注重推理Decode阶段和练习场景。因为 推理Decode阶段和练习对互联带宽和访存带宽请求 高,我们开发了HiZQ 2.0,使内存容量到达144GB,内存拜候 带宽到达4TB/s。同时把互联带宽提拔到了2TB/s。其次,支撑 了FP8/MXFP8/MXFP4/HiF8数据格式。 Ascend 950DT 将在2026年Q4推出。 第三颗是在筹划 中的芯片Ascend 960。它在算力、内存拜候 带宽、内存容量、互联端口数等各类 规格上比拟 Ascend 950翻倍,年夜 幅度提拔练习、推理等场景的性能;同时还支撑 华为自研的HiF4数据格式。它是目前业界最优的4bit精度实现,能进一步提拔推理吞吐,而且比业界FP4筹划 的推理精度更优。 Ascend 960将在2027年四季度推出。 末了一颗是在筹划 中的Ascend 970,这颗芯片的一些规格还在品评辩说 中。总体方向是,在各项指标上年夜 幅度升级,全面升级练习和推理性能。目前的初步考虑是,比拟 Ascend 960,Ascend 970的FP4算力、FP8算力、互联带宽要全面翻倍,内存拜候 带宽至少增加1.5倍。Ascend 970筹划在2028年四季度推出。年夜 家届时可以等待它的惊人表现。 这是刚才先容的昇腾芯片的主要详细规格和路标,总体上,我们将以险些一年一代算力翻倍的速率,同时环绕 更易用,更多半 据格式、更高带宽等方向连续演进,连续满意AI算力不停增加 的需求。可以看到,比拟 Ascend 910B/910C,从Ascend 950开端 的主要变化包括: 引入SIMD/SIMT新同构,提拔编程易用性; 支撑 更加 丰硕 的数据格式,包括FP32 /HF32 /FP16/BF16/FP8/MXFP8/HiF8/MXFP4/HiF4等; 支撑 更年夜 的互联带宽,其中950系列为2TB/s,970系列提拔到4TB/s; 支撑 更年夜 的算力,FP8算力从950系列的1 PFLOPS提拔到960的2 PFLOPS、970的4 PFLOPS;FP4算力从950的2 PFLOPS提拔到960的4 PFLOPS、970的8 PFLOPS; 内存容量渐渐更加,而内存拜候 带宽将翻两番。 有了昇腾芯片为基础,我们就可以或许打造满意客户需求的算力解决 筹划 。从年夜 型AI算力基础办法创立 的技术方向看,超节点已经成为主导性产品形态,并正在成为AI基础办法创立 的新常态。超节点究竟上就是一台能学习、思索、推理的计算 机,物理上由多台机器组成 ,但逻辑上以一台机器学习、思索、推理。跟着 算力需求的连续增加 ,超节点的范围 也在连续、快速增年夜 。 本年3月份,华为正式推出了Atlas 900超节点,满配支撑 384卡。因为是超节点,这384颗Ascend 910C芯片,可以或许像一台计算 机一样工作,最年夜 算力可达300 PFLOPS。到目前为止,Atlas 900依然是举世算力最年夜 的超节点。年夜 家经常听到的CloudMatrix384超节点,是华为云基于Atlas 900超节点构建的云办事 实例。Atlas 900超节点自上市以来,已经累计摆设高出300套,办事 20多个客户,涵盖互联网、电信、制造等多个行业。可以说,Atlas 900于2025年,开启了华为AI超节点的征程。 今天 ,连合我们已经推出或正在研发中的昇腾芯片,我将为年夜 家带来更多超节点和集群产品。如今进入今天 最激动听 心的时刻,就是新产品发布环节。 今天 我要发布的第一款产品,Atlas 950超节点,基于Ascend 950DT打造。 Atlas 950超节点支撑 8192张基于Ascend 950DT的昇腾卡,是Atlas 900超节点的20多倍,我们风俗称呼的昇腾卡,每张卡对应一颗Ascend 950DT芯片,8192张昇腾卡等同于8192颗Ascend 950DT芯片。 Atlas 950超节点满配包括由128个计算 柜、32个互联柜,共计160个机柜组成 ,占地面积1000平方米摆布 ,柜间接纳全光互联。总算力年夜 幅度提拔,其中,FP8算力到达8E FLOPS,FP4算力到达16E FLOPS。互联带宽到达16PB/s,这个数字意味着,Atlas 950一个产品的总互联带宽,已经高出今天 举世互联网峰值带宽的10倍有余。 Atlas 950超节点的上市时光 是:2026年四季度。 我们很自尊的看到,Atlas 950超节点,至少在未来多年都将坚持 是举世最强算力的超节点,而且在各项主要本事上都远超业界主要产品。其中,比拟 英伟达同样将在明年下半年上市的NVL144,Atlas 950超节点卡的范围 是其56.8倍,总算力是其6.7倍,内存容量是其15倍,到达1152TB;互联带宽是其62倍,到达16.3PB/s。即使是与英伟达筹划2027年上市的 NVL576比拟 ,Atlas 950超节点在各方面依然是领先的。 算力、内存容量、内存拜候 速率、互联带宽等本事的年夜 幅度增强,为年夜 模型练习惯 能和推理吞吐带来明显提拔。比拟 华为已经推出的Atlas 900超节点,Atlas 950超节点的练习惯 能提拔17倍,到达4.91M TPS。经过过程 支撑 FP4数据格式,Atlas 950超节点的推理性能提拔达26.5倍,到达19.6M TPS。 8192卡超节点并不是我们的尽头,我们还在继续积极。我今天 发布的第二款超节点产品,Atlas 960超节点。基于Ascend 960,Atlas 960超节点最年夜 可支撑 15488卡。Atlas 960超节点 由176个计算 柜,44个互联柜,共220个机柜,占地面积约2200平方米。 Atlas 960超节点的上市时光 是:2027年四季度。 陪同卡的范围 的再次升级,Atlas 960超节点让我们在AI超节点的上风再度增强。基于Ascend 960,其总算力、内存容量、互联带宽在Atlas 950基础上再翻倍。其中,FP8总算力将到达30E FLOPS,而FP4总算力将到达60 EFLOPS;内存容量到达4460TB,互联带宽到达34PB/s。年夜 模型练习和推理的性能比拟 Atlas 950超节点,将别离 提拔3倍和4倍以上,到达15.9M TPS 和80.5M TPS。经过过程 Atlas 950和Atlas 960,我们对于为人工智能的恒久快速发展提供可连续且充裕算力,充满信念 。 超节点已经重新定义 AI基础办法的范式,但不仅仅局限于AI。在通用计算 领域,我们同样以为,超节点技术可以或许带来很年夜 的代价。从需求角度考虑,金融核心营业 等目前仍旧有部分承载在年夜 型机和小型机之上,比拟 普通办事 器集群,它们对办事 器的性能和靠得住 性有更高的诉求,通用计算 超节点在这两点上恰好契合需求。从技术角度考虑,超节点同样可以为通算领域注入全新活气 。 因此,鲲鹏处理器主要环绕 支撑 超节点,更多核、更高性能等方向连续演进。同时,经过过程 自研的双线程灵犀核,使鲲鹏处理器能便利 支撑 更多线程。 2026年Q1,我们将推出Kunpeng 950处理器,包括两个版本,别离 是:96核/192线程和192核/384线程;支撑 通用计算 超节点;安全方面新增四层隔离,成为鲲鹏首颗实现秘密计算 的数据中心处理器。 2028年Q1,鲲鹏处理器将在芯片微架构、先进封装技术等领域连续突破 关键技术,将再次推出两个版本,别离 是高性能版本,96核/192线程,单核性能提拔50%+,主要面向AI host、数据库等场景。以及高密版本,不少于256核/512线程,主要面向假造化、容器、年夜 数据、数仓等场景。 接下来是今天 我发布的第三款产品:TaiShan 950超节点,基于Kunpeng 950打造,举世首个通用计算 超节点,其最年夜 支撑 16节点,32个处理器,最年夜 内存48TB,同时支撑 内存、SSD、DPU池化。 这款产品不只是通用计算 领域的一次技术升级,除了年夜 幅提拔通用计算 场景下的营业 性能,还能帮助金融体系破解核心难题。当前年夜 型机、小型机更换的核心挑衅 是数据库散布 式改造,而基于TaiShan 950超节点打造的 GaussDB多写架构,无需改造,但性能提拔2.9 倍,最终 可平滑 替代年夜 型机、小型机上的传统数据库。TaiShan 950加上散布 式GaussDB将成为各类年夜 型机、小型机的闭幕者,彻底代替各类 应用处 景的年夜 型机和小型机以及Oracle的Exadata数据库办事 器。 除了核心数据库场景,TaiShan 950超节点在更普遍 的场景里,表现也很亮眼:比如假造化情况的内存使用率提拔20%,在Spark年夜 数据场景,实时数据处理时光 收缩30%。 TaiShan 950超节点上市时光 是:2026年一季度,敬请等待。 超节点的代价,不仅仅体如今智算和通算传统营业 领域。互联网产业普遍 应用的推荐体系,正在从传统推荐算法向天生式推荐体系演进。我们可以基于TaiShan 950和Atlas 950打造成肴杂超节点,为下一代天生式推荐体系打开全新架构方向。 一方面,经过过程 超年夜 带宽、超低时延互联以及超年夜 内存,肴杂超节点组成 超年夜 共享内存池,支撑 PB级推荐体系嵌入表,从而支撑超高维度用户特性;另一方面,肴杂超节点的超年夜 AI算力,可以或许支撑 超低时延推理和特性检索。因此,肴杂超节点是面向下一代天生式推荐体系的解决 筹划 的全新选择。 年夜 范围 超节点把智算和通算的本事都推向新的高度,同时也对互联技术提出了庞年夜 挑衅 。华为作为联接领域的领导者,当然不惧挑衅 。在定义 和设计Atlas 950、Atlas 960两个超节点的技术规格时,我们遭遇 到了互联技术的伟年夜 挑衅 ,主要在两个方面: 第一是如何 做到长距离而且 高靠得住 。年夜 范围 超节点机柜多,柜间联接距离长,当前电互联和光互联技术都不能满意需求。其中,当前的电互联技术在高速时联接距离短,最多只能支撑 两柜互联,而当前的光互联技术固然可以把长距离的多机柜联接在一起,但无法满意靠得住 性需求。 第二是如何 做到年夜 带宽而且 低时延。当前跨柜卡间互联带宽低,和超节点的需求差距达5倍;跨柜的卡间时延年夜 ,当前互联技术最好只能做到3微秒摆布 ,和Atlas 950/960设计需求仍旧有24%的差距,其时延已经低至2~3个微秒时,已经逼近物理极限,哪怕0.1微秒的提拔,挑衅 都很年夜 。 华为基于三十多年修建 的技术本事,经过过程 体系性立异 ,彻底解决 了当前技术存在的标题,超标达成Atlas 950/960超节点的设计需求,使万卡超节点成为年夜 概。 起首,为相识决 长距离且高靠得住 标题,我们在互联协议 的物理层、数据链路层、收集 层、传输层等每一层都引入了高靠得住 机制;同时在光路引入了百纳秒级故障检测和保护 切换,当涌现 光模块闪断或故障时,让应用无感;而且,我们重新定义 和设计了光器件、光模块和互联芯片。这些立异 和设计让光互联的靠得住 性提拔100倍,且互联距离高出200米,实现了电的靠得住 和光的距离。 其次,为相识决 年夜 带宽且低时延标题,我们突破 了多端口聚合与高密封装技术,以及同等架构和同一协议 ,实现了TB级的超年夜 带宽,2.1微秒的超低时延。正是因为一系列体系性、原创性的技术立异 ,我们才攻克了超节点互联技术,满意了高靠得住 、全光互联、高带宽、低时延的互联请求 ,让年夜 范围 超节点成为了年夜 概。 为了达成Atlas 950/960超节点对互联的技术请求 ,为了实现万卡超节点还能是一台计算 机,华为开创了超节点架构并开创了新型的互联协议 ,可以或许支撑万卡级超节点架构。基于这个互联协议 的超节点架构的核心代价主意 是:万卡超节点,一台计算 机,也就是说,经过过程 该互联协议 ,把数万范围 的计算 卡,联接成一个超节点,可以或许像一台计算 机一样工作、学习、思索、推理。 在技术上,我们总结以为,万卡级超节点架构应当 具备6年夜 特性,别离 是总线级互联、同等协同、全量池化、协议 归一、年夜 范围 组网、高可用性。我们为这个面向超节点的新型互联协议 取名“灵衢”,英文名称:UB,UnifiedBus 今天 ,我们正式发布灵衢、UnifiedBus,一个面向超节点的互联协议 。 同时,我公布,华为将开放灵衢2.0技术规范。为什么从灵衢2.0开端 开放?究竟上,灵衢的研究是从2019年开端 的,因为众所周知的缘故原由,先进工艺不成 获得,我们必要从多芯片上突破 ,希望把更多的计算 资本 联接在一起。我们取了一个名字叫UnifiedBus,简称UB,中文名字“灵衢”,意味着类似九省通衢,实现年夜 范围 算力的联通。基于灵衢 1.0 的Atlas 900超节点自2025年3月开端 交付,至今已商用摆设300多套,灵衢1.0技术获得 充分验证。在灵衢1.0的基础上,我们继续丰硕 功效 ,优化性能,提拔范围 ,进一步完善了协议 ,形成了灵衢2.0,前面发布的Atlas 950超节点就是基于灵衢2.0。 我们以为灵衢2.0具备了开放的条件 ,为了更普遍 地促进互联技术发展和产业提高 ,今天 华为决议 开放灵衢2.0技术规范,接待产业界伙伴基于灵衢研发相关产品和部件,共建灵衢开放生态。 我在客岁HC会上夸张 过,基于中国可获得的芯片制造工艺,我们积极打造“超节点+集群”算力解决 筹划 ,来连续满意算力需求。今天 已经先容了三个超节点产品。灵衢既为超节点而生,是面向超节点的互联协议 ,也是构建算力集群产品最优的互联技术。 接下来为年夜 家带来两个集群产品:起首是,Atlas 950 SuperCluster 50万卡集群! Atlas 950 SuperCluster集群由64个Atlas 950超节点互联组成 ,把1万多机柜中的52万多片昇腾950DT组成 为一个整体,FP8总算力可达524 EFLOPS。上市时光 与Atlas 950超节点同步,即2026年Q4。 在集群组网上,我们同时支撑 UBoE与RoCE两种协议 ,UBoE是把UB协议 承载在以太网上,让客户可以或许使用现有以太交换机。比拟 传统RoCE,UBoE组网的静态时延更低、靠得住 性更高,交换机和光模块数量都更节省,所以,我们推荐UBoE。 这就是我们的Atlas 950 SuperCluster集群。比拟 当宿世界上最年夜 的集群 xAI Colossus,范围 是其2.5倍,算力是其1.3倍,是当之无愧的全世界最强算力集群!无论是当下主流的千亿浓密 、希罕年夜 模型练习任务,照旧未来的万亿、十万亿年夜 模型练习,超节点集群都可以成为性能强横的算力底座,高效稳定地支撑 人工智能连续立异 。 相应的,在2027年Q4,我们还将基于Atlas 960超节点,同步推出Atlas 960 SuperCluster,集群范围 进一步提拔到百万卡级,FP8总算力到达2 ZFLOPS!FP4总算力到达4 ZFLOPS。而且,它同样也支撑 UBoE与RoCE两种协议 ,在UBoE协议 加持下,性能与靠得住 性同样更优,而且,静态时延和收集 无故障时光 上风进一步扩年夜 ,因此继续推荐UBoE组网。经过过程 Atlas 960 SuperCluster,我们将连续加速客户应用立异 ,探索智能程度新高。 很高兴今天 给年夜 家带来一系列新产品,我们希望和产业界一起,以开创的灵衢超节点互联技术,引领AI基础办法新范式;以基于灵衢的超节点和集群连续满意算力快速增加 的需求,推动听 工智能连续发展,发明 更年夜 的代价,谢谢! |


2025-05-03
2025-03-05
2025-02-26
2025-03-05
2025-02-26


官方手机版

微信公众号

商务合作




