
(文/视察 者网 张广凯 编纂 /吕栋) 9月24日的云栖大会主论坛上,阿里巴巴集团CEO、阿里云智能集团董事长兼CEO吴泳铭举行了25分钟的PPT演讲。 对于一向低调的阿里“第一个程序员”而言,这并不平常。要知
|
 (文/视察 者网 张广凯 编纂 /吕栋) 9月24日的云栖大会主论坛上,阿里巴巴集团CEO、阿里云智能集团董事长兼CEO吴泳铭举行了25分钟的PPT演讲。 对于一向低调的阿里“第一个程序员”而言,这并不平常。要知道,客岁的云栖大会,吴泳铭还只是以读稿的形式 发言 ,乃至略显紧张。 比现场观众反应 更热闹 的,是资源市场。几乎 就在吴泳铭演讲结束的同时,港股阿里巴巴股价快速拉升,当日大涨9.16%。 纵然在中国科技资产重估的大配景下,像阿里如许信息高度透明的大块头突然出现如此涨幅,仍然是不平常的。投资者看到了什么?
 吴泳铭的演讲中的确透露了一些增量信息和乐观判断,好比: 大模型作为下一代的操纵体系,将会吞噬软件; 将来全世界可能只会有5-6个超级云计算平台; 阿里云在三年3800亿的AI根本 设施建筹划划之外将追加投入; 2032年阿里云全球数据中央的能耗规模将提升10倍。 但纵然是纵观全体 云栖大会,真正超预期的信息也并不多,生怕 不足以解释市场的猛烈反应 。无论是大模型的研发迭代,还是AI云“一哥”的竞争,乃至芯片和算力结构,阿里云都不追求“憋大招”,而是在肯定 性最强的标的目标 上试图步步为营 。 究竟上,当日的市场反应 更像是此前相称长一段时光 内积聚的情绪开释,阿里云的小步快跑,让一种模糊的印象正逐渐获得 加强——或许阿里并不总是占据AI行业的“头条”,但是 其大而全的深厚技术积聚会会议长期让自己立于不败之地。 就像吴泳铭本人一样,阿里作为“技术男”的形象愈发深入 人心 。而对体量足够大的阿里来说,抑制 有时间也是一种上风。 “大就是好” 从岁首年月 开始 ,阿里云作为“AI界汪峰”的名号不胫而走。 因由是大岁首年月 一,阿里云宣布 通义千问旗舰版模型Qwen2.5-Max,其综合能力凌驾DeepSeek V3,成为最强的国产非推理模型。 选在这个时光 点宣布 ,阿里云显然是瞄准了春节期间的C端流量。 但是 结果大家都知道了,就在几天前,DeepSeek宣布 了推理模型R1,成为全体 春节期间绝对意义上的主角。 此后,尽管DeepSeek迭代速度不尽人意,Qwen则持续刷榜,可是在"大众," 的认知中,Qwen始终难以同DeepSeek反抗 。 而阿里云似乎也徐徐放下了“抢头条”的执念。 在本次云栖大会上,阿里云CTO周靖人一口气宣布了7款大模型的升级 。不过,相比于春节那次宣布 ,此次的7连发少了几分锐意 。 以最新的旗舰模型Qwen3-Max为例,其实早在本月初,其Preview版就已经在深夜低调上线,宣布 通义进入万亿参数期间。 在LMArena上,Qwen3-Max Preview的评分已经出炉,排在文本处理能力的第三位,能力介于ChatGPT-5-chat和ChatGPT-5-high之间,是前十名中独一 的中国大模型。
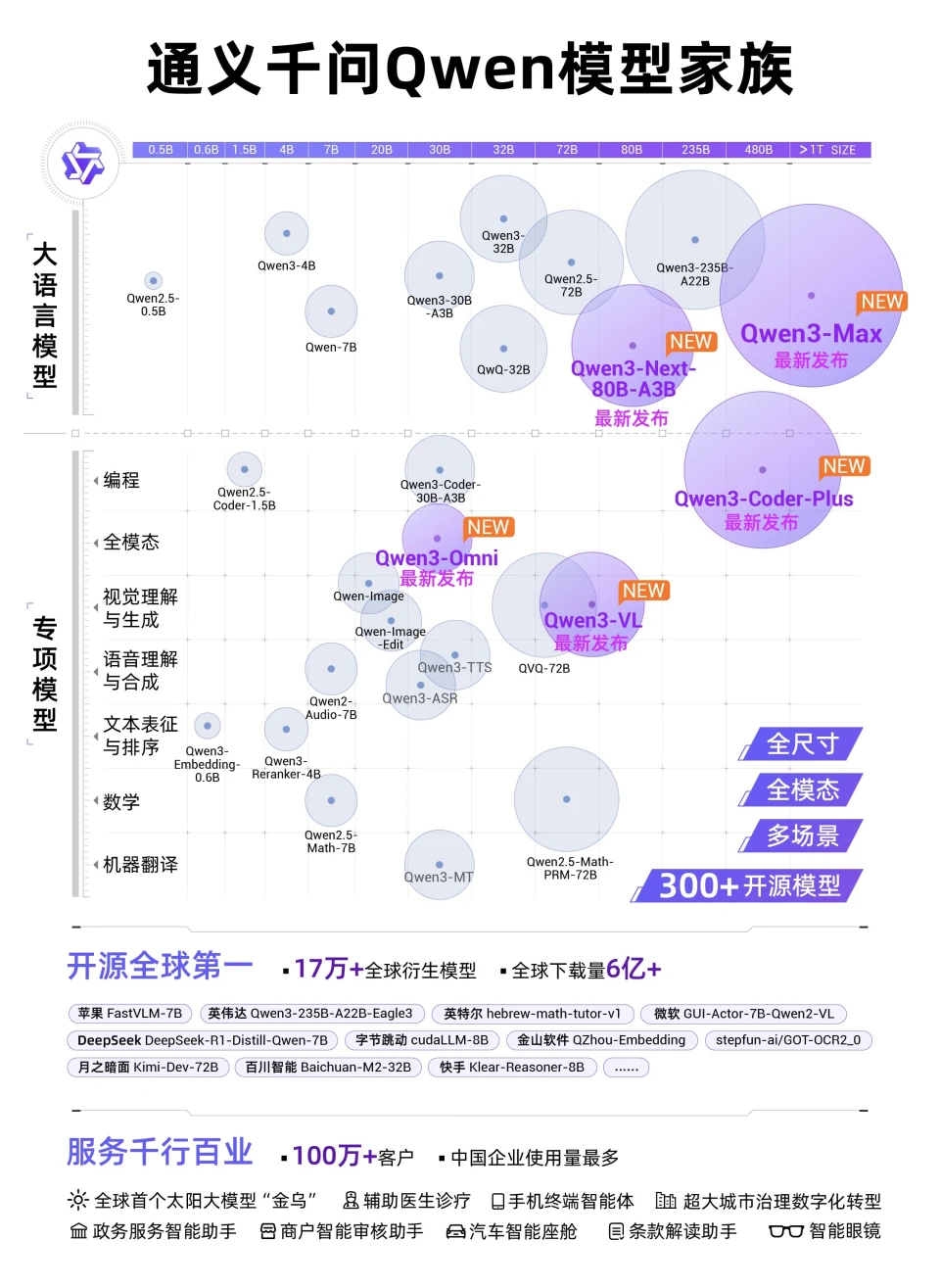
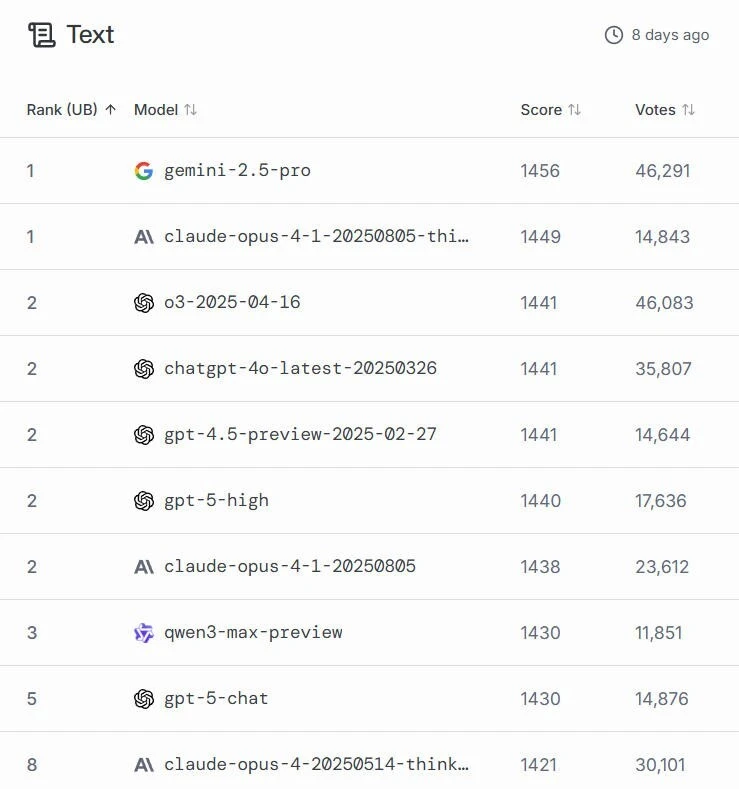 (注:LMArena接纳了经过复杂调整的排名方式,旨在去除一些统计偏差,其排名反应 的是模型能力品级,而非完整 取决于其身前模型的数量) 周靖人指出,Qwen3-Max的正式版本比Preview又有了显着提升,其Instruct版本在代码能力和Agent对象 调用能力上都到达一梯队程度,Thinking版本则在数学能力测试中取得国内最佳成绩。 在先容Qwen3-Max时,通义官方使用了一个词:“大就是好”。 换句话说,Qwen3-Max能力提升的核心仍然是Scaling Law。除了万亿参数量之外,其预训练数据量也从18T提升到36T。 通义官方认为 ,当前有部分学者认为 预训练的Scaling Law即将逼近上限,而Qwen3-Max的机能 冲破 体现,继续增大数据、模型参数,依然能锻造出更强的模型,赐与 了大家更多的信念 。 除了参数量和数据量的提升外,Qwen3-Max也在紧跟算法立异 的最新标的目标 。 通义实行室算法专家先容,此前Qwen3宣布 后,团队总结了模型仍然存在的缺点 ,即混淆思索机能 有损、强化进修 不稳定、高低 文128k不够 。 为此,Qwen3-Max拆分出了Instruct和Thinking两个版本,分别 注重快慢思索;在强化进修 算法上引入了自研的GSPO,取代了DeepSeek接纳的GRPO,并将高低 文扩大 到1M。 通义还宣布 了下一代根本 模型架构Qwen3-Next,主打超稀疏的MoE架构,模型总参数80B,仅激活3B即可媲美当下Qwen3旗舰版235B的结果。 视察 者网了解 到,这重要得益于线性留意力和自研的门控留意力相结合的混淆架构、多 token 猜测(MTP)机制等,并将激活专家占比从1:16进一步镌汰为1:50,使得训练和推理效率都大大提升。 其实,这些技术层面的立异 仍然可以用“大就是好”来概括——固然并非颠覆性立异 ,却试图比对手走得更远一步。 而最核心的指导头脑,也被归纳为Scaling is all you need——大模型的标的目标 ,依然是更大。
 类似地,通义此次宣布 了多款多模态模型的升级 ,以及全模态融会 的Qwen3-Omni。阿里云通义大模型业务总经理徐栋对视察 者网先容,通义团队信赖模型架构走向统逐一定是将来的趋向 ,包罗多模态的统一和快慢思索的统一。 但从行业来看,架构统一仍然处于早期阶段,包罗通义和阶跃星辰等多模态玩家,眼下追求的也不是拿出一个超级模型,而是尽可能多地在各个模态上普遍 结构。这未尝不是另一种“大就是好”。 或许"大众," 层面会对一次颠覆性的立异 更加 印象深入 ,但周靖人对视察 者网直言,“模型的成长 是一个循规蹈矩的过程,而不是‘憋大招’的逻辑,海表里全体 厂商都是渐进式成长 起来的,重要的是加速模型迭代和立异 的速度。” 阿里云方面也夸大,自2023年开源第一款模型以来,通义大模型在全球下载量冲破 6亿次,衍生模型冲破 17万个,已成长 成为全球第一开源模型。
 鏖战与抑制 阿里云的“大”,固然不但仅是模型的大,更在于此中国最大云服务商的底色。 故意思的是,环绕 AI云的规模,国内同行间最近正睁开另一场剧烈的“抢头条”暗战。 此中最惹人 凝视 的无疑是字节旗下的火山引擎。 就在云栖大会期间,许多人发明 ,阿里“大本营”杭州的机场航站楼广告,却被火山引擎占领了。
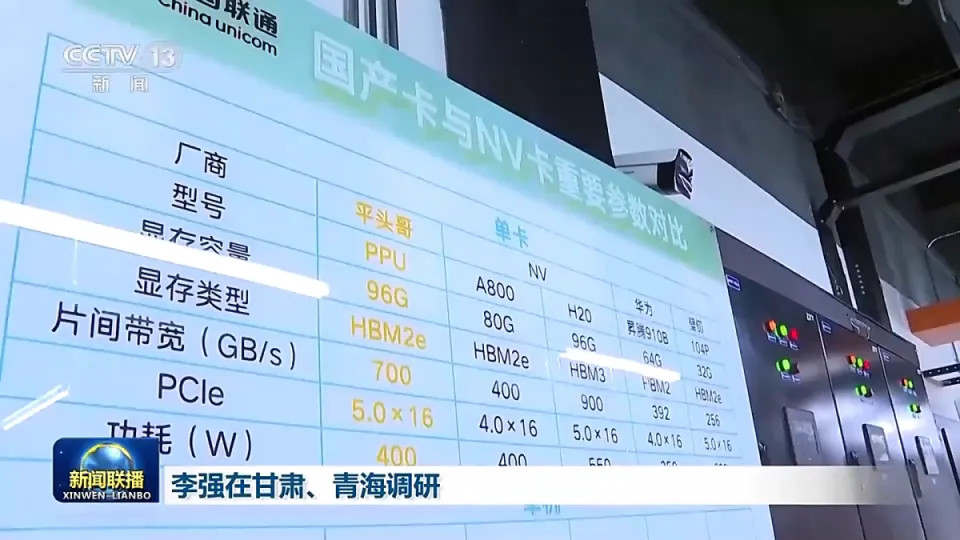
 乃至,火山引擎的开屏广告,还出现在了本该是竞争对手的百度舆图APP上。 在这些广告上,火山引擎试图打造自己“大模型第一云”的心智。 就在两三年前,火山引擎还只是服务字节内部生态为主的搅局者,但是 国际数据公司IDC本月宣布 的一份报告却体现,2025年上半年,中国公有云上大模型调用量达536.7万亿tokens,火山引擎以49.2%的市场份额位居中国市场第一,而阿里云以27%屈居第二。这内里还没有包罗豆包等字节自家大模型产品的调用数据。 固然,这个数据仅仅体现了MaaS市场的部分面貌。因为 Qwen家族模型以开源为主,大量客户并非以MaaS形式 去调用API,而是自己在阿里云上部署模型,这部分数据并没有被统计进去。 Omdia几乎 同时宣布 的一份报告,则包罗了IaaS、PaaS与MaaS等团体口径,体现2025年上半年中国AI云市场中阿里巴巴占比到达35.8%,市场份额相称于二到四名之和。 沙利文不日 宣布 的报告则指出,在已接纳生成式AI的财产中国500强中,超53%企业选择阿里云,体现出阿里云在大客户端的传统上风。 辘集 宣布 的各种差别口径报告,折射出云厂商之间的剧烈暗斗。不过在另一面,直接的价格战似乎正在降温。 低价是火山引擎最强大的武器 。尽管火山引擎总裁谭待否认“亏钱换市场”,但他也仅仅指出火山的毛利为正。 今年6月,豆包1.6又首创按“输入长度”区间定价,使综合使用本钱降至豆包1.5深度思索模型的三分之一。 但是 今年以来,包罗DeepSeek在内的多家大模型调用价格开始 不降反涨,阿里云的最近一次周全 降价 也停留在2024年的最后一天。 接近阿里云的人士向视察 者网透露,阿里云不会再以亏钱的代价做大营收,新的领导层对此想得非常清楚。 其进一步指出,在过去 多年中,阿里云经历了华为云、运营商云等多个挑衅 者,仍能坚持 市场领先职位,现在的心态也更加 自大。 在本次大会上,我们还可以看到更多阿里云抑制 的信号。 比方,在时下话题度颇高的超节点技术上,尽管阿里云也宣布 了类似产品,但并未凸起 宣传。一位阿里云技术专家指出,超节点的上风场景仅仅在于分布式推理,但是 在训练环节并无显著提升,且随着超带宽域增长会带来暴虐的可靠性困难。 许多参会者都向视察 者网提到,相比于别的厂商的类似运动,云栖大会有着更浓重的技术和务实风格。 阿里云更显著的务实风格固然还是表现在C端市场。当字节豆包、腾讯元宝纷纷依托自身外交生态大力推广自家聊天应用 时,通义APP则始终不肯意费钱买用户。在国内C端付费极不蓬勃 的生态下,如许的选择自有合理性。 但是 与传统的云服务市场差别,AI大模型势必将是深度进入C端市场的变革,并且DeepSeek和豆包都证实,其C端体现也会间接影响B端心智。阿里云的抑制 是否明智,仍然有待时光 查验。 硬件的变数 究竟上,尽管没有高调宣传,阿里云在AI Infra层面的渴望正在加速。 本月初有媒体消息称,阿里已经开发了一款新的AI芯片,适用 于大模型推理场景,能够 接近英伟达H20的程度,由国内晶圆厂代工,并且还兼容英伟达生态。 此后,央视《消息联播》公开报道了中国联通三江源绿电智算中央项目建设成效,此中阿里平头哥拿下最大订单,以16384 张算力卡供应 1945P算力,大致与上述消息相符 。
 在收集 层面,阿里云也在云栖大会上宣布 了新一代高机能 收集 HPN 8.0接纳训推一体化架构,存储收集 带宽拉升至800Gbps,GPU互联收集 带宽到达6.4Tbps,可支持单集群10万卡GPU高效互联,为万卡大集群供应 高机能 、肯定 性的云上根本 收集 。 再加上128超节点等技术,阿里云在AI Infra上的全栈结构已经根本成型。在英伟达入华阻力越来越大的当下,阿里云有望在国产替代大潮中分得远超此前预期的份额。 但是 ,随着越来越多的云服务商开始 自研芯片,它们与第三方供应商的关系或许也变得微妙起来。 不日 有消息称,在芯片范畴根本 相对单薄的字节,也已经与台积电合作研发两款AI芯片,有望于2026年量产。 目前,阿里云和字节都采购了大量华为昇腾芯片。但是 华为云近期也实施了“史上最大规模构造优化”,大幅紧缩传统云服务业务,将重心进一步转向AI算力。 如此一来,阿里云和火山引擎作为客户厂商,是否会在同华为云的竞争中处于天赋劣势?其自研芯片能否快速支持起算力端需求? 乃至,别的第三方算力芯片供应商,是否也会在大厂剧烈的竞争中走向阵营绑定?差别阵营的技术门路和贸易风险又会怎样影响行业格局? 国产芯片的集团化崛起,固然 是国家之幸,但身处局中者,也难免面对伟大 变数。 |


2025-05-03
2025-03-05
2025-02-26
2025-03-05
2025-02-26


官方手机版

微信公众号

商务合作




