
AI年夜 模型也好,智能体也好,在各种测评榜上刷得不亦乐乎。对于跟踪模型进展,发现模型能力上限确实 有用;不过衡量的是模型的抽象能力,而不是具有经济价值 的产出。从投资界、财产界到公众,对于人工智能的刷榜和演
|
AI年夜 模型也好,智能体也好,在各种测评榜上刷得不亦乐乎。对于跟踪模型进展,发现模型能力上限确实 有用;不过衡量的是模型的抽象能力,而不是具有经济价值 的产出。 从投资界、财产界到公众,对于人工智能的刷榜和演示能力固然感到惊艳,但他们关注 的重心,正在从“核弹级的炸裂”,转移到真正的拷问,花这么多钱和这么多名校绝顶智慧的孩子,搞这些东西,最终用来干什么? 就是AI的经济价值 有多年夜 ,在实际工作中,替换或者增强人类的潜力有多年夜 ; 假如很年夜 的话,如今发挥出了多少?AI交付实际工作的能力,可能更需要衡量,假如说如今派上用场,人们还不放心的话。 硅谷的AI雇用独角兽公司Mercor也想知道,帮助那些顶级AI年夜 厂和独角兽企业找到的学霸们,弄出来的年夜 模型,除了又当学霸之外,还醒目什么实际工作。 “人工智能在奥林匹克数学方面已经超越人类,但这些能力可能与经济成长 脱节。拥有一万个博士学位固然很好,但拥有一个能靠得住 地帮你报税的模型就更好了。” 他们设计了一个AI生产力指数 (AI Productivity Index, APEX),首先选取了4个最高经济价值 的白领行业进行测试,约请了投行、咨询、司法 、医学的资深专家,把他们在实际工作中遇到和办理的问题搬出来,让23个年夜 模型下到职场,当下这四个行业的“牛马”:投资银行助理、办理 参谋 、年夜 型律师 变乱所助理和初级保健医生 (MD)。 表现如何?结果如下: 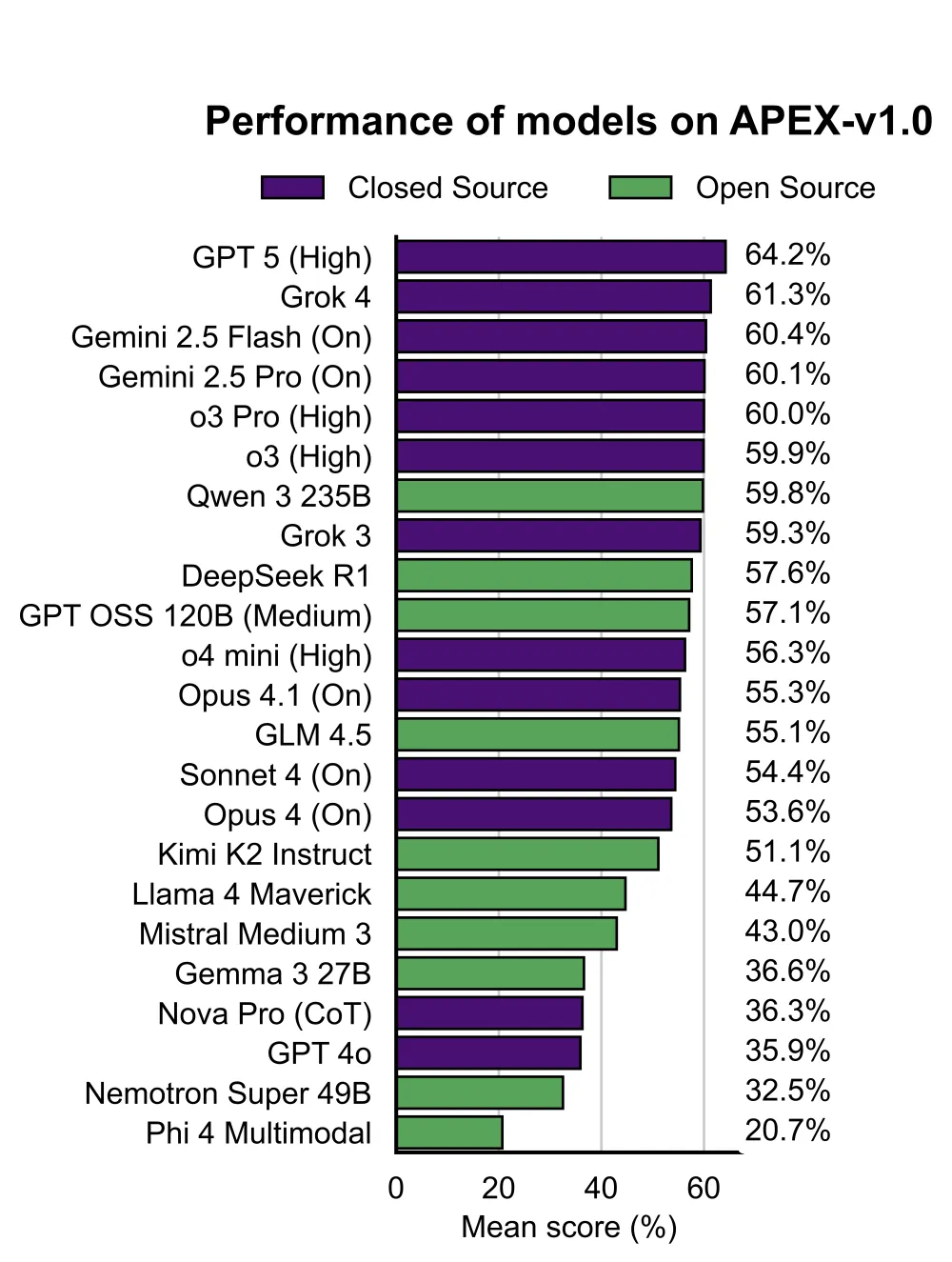 排名前五的,都达到了及格线60分,排名第5-10名的,接近及格线。总体来看,OpenAI的模型家族,当牛马的能力最强。 GPT-5、Grok4、Gemini 2.5位居前三,值得关注 的是,Qwen 3 235B和DeepSeek R1分别 获得 第7名和第9名,在开源模型中排名前两位,GPT OSS 120B(Medium)名列开源第三。相比之下,编程明星Sonnet 4 表现一般。 下面这个测试的案例,来自一家律所近来遇到的一个真实客户,这位音乐家的版权继承人遇到了贫苦,想找律师 帮助办理问题。律所助理要对这个客户的正当继承问题做出初步判断。该测试涉及到22条标准,8个司法 来源 ,不凌驾10万个token。  诸云云类的案例,统共200个,每个行业50个,分别 由20名左右资深专家设计。Mercor通过本身的平台找到了这些专家:
这些专家共同创建了一个数据库APEX-v1.0 ,全部 的案例和提醒 ,都来自真实天下。这些任务,专家们本身干,一般要用1-8个小时,均匀3.5小时。 专家们找到权威和真实的来源 ,创建了标准和评分细则。然后由Mercor去汇集 各模型的回复,再由语言模型按照 专家标准打出分数。关于为什么用语言模型进行评判,以及它们与人工专家评判之间的差别,可以参考论文了解细节。 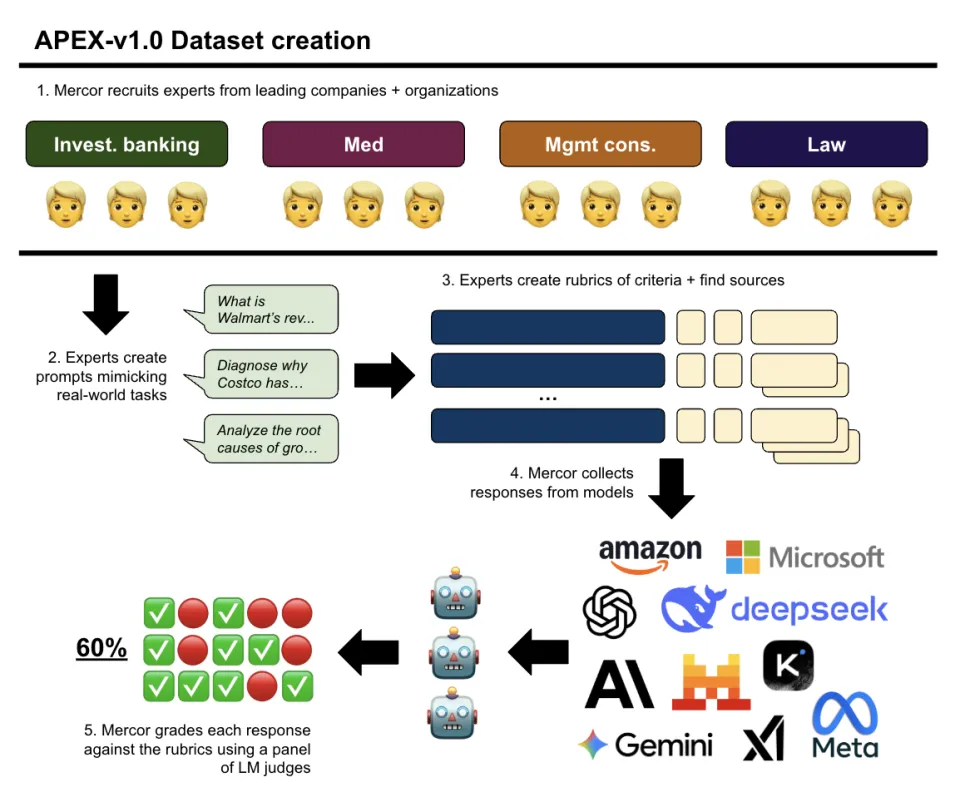 Mercor称APEX是首个基于AI执行具有经济价值 的常识 工作能力的基准测试。APEX-v1.0 测试了 23 个模型,除亚马逊的 Nova Pro(宣布 于 2024 年 12 月)和 OpenAI 的 GPT 4o(最初宣布 于 2024 年 5 月,最后 更新于 2024 年 11 月)外,全部 模型均于 2025 年宣布 。最新的模型是 GPT 5(Thinking = High),宣布 于 2025 年 8 月初。模型相应于 2025 年 8 月初网络。13 个闭源模型通过各自的 API 拜候 ,10 个开源模型通过开源提供商拜候 。 测试另有些发现,值得拿出来说下: 开源和闭源模型的机能 有何不同? 照旧有差距的。闭源模型的均匀得分为55.2%,而开源模型的均匀得分为 45.8%,下降 了9.4个百分点。在成对胜率方面,差距更年夜 ,分别 为57.6% 和40.2%,下降 了15个百分点以上。也有两个破例,Qwen3 235B和DeepSeek R1照旧能和有些前沿闭源模型掰手腕的。 机能 更强盛的模型(工作中)表现是否更好? 纷歧 定,并且 这些模型的“测验”表现和“工作”表现,偶然反差挺年夜 的。Claude模型家族的Opus 4在全部 四个机能 指标上的表现都比Sonnet 4差。o3 Pro在均匀分数方面仅比o3高 0.1%,在其他三个指标上的表现更差。Gemini 2.5 Flash的均匀分数比 Gemini 2.5 Pro高 0.3%,它在成对得胜率和排名第一的次数百分比喻 面也表现精彩。这些结果表白 ,功效 更强盛的模型版本(平日 价值 更高)并纷歧 定更擅长 执行实际天下中高经济价值 的任务。同一家族中不同代模型的机能 略有提升。 相应是不是越长越好? Qwen 3 235B和DeepSeek R1都提供了年夜 量关于其脑筋 进程 的细节,并且 高度反复 ,且在某些处所 偏离主题。然而,因为 没有对长度进行处分 ,是以 两者都获得 了较高的均匀分数,并且 它们提供了足够多的精确信息来通过许多标准。另一方面,一些表现较差的模型(比喻 GPT 4o、Phi 4 Multimodal 和Nova Pro(Thinking = CoT))的均匀复兴长度最短(分别 排名第一、第二和第四)。剖析 表现复兴长度与结果之间干系度险些为零。 年夜 家最关心 的问题,哪个领域牛马最有可能被AI增(替)强(代)。 得分依次为司法 56.9%,办理 咨询52.5%,投资银行47.6%,医学47.5%。看来AI在司法 行业的表现最好,医学最难。APEX 的将来迭代会涵盖更多岗亭 ,下面4个可能是软件工程、教学、保险和平面设计。 最后 ,AI 模型提升劳动生产率的能力,正日益成为研讨 的热点 , 中国这方面的研讨 相对较少,也许更多是直接把模型当牛马到职场上去溜溜了? -- 论文原文及参考: https://arxiv.org/html/2509.25721v2 https://mercor.com/blog/introducing-apex-ai-productivity-index/ |


2025-05-03
2025-03-05
2025-02-26
2025-03-05
2025-02-26


官方手机版

微信公众号

商务合作




