近来618开始了,又到了一年一度换设备的日子。端午节之后,就有好几个朋侪问我,你的电脑用的是啥配置的。我一般 就会发两张图过去。他们一般 就会发一个地铁老头看手机的表情,然后问:想买一台学AI的笔记本,有没有
   我每次总会反问一句话: 学AI?你主要学啥。 对方就会跟我说,搞个知识 库,画画图,做做AI编程,学学AI视频啥的。 这时候我就会问他们,你是有很多的不能上云端的隐私数据吗,还是你要在当地玩一些自界说大概很特别的工作流? 这时候有朋侪就懵逼了。。。 说啊?这些是啥?玩AI不必要好配置的吗。 反过来给我也问懵了。 所以,我以为,我还是想写一篇文章,来给大家聊一聊,到底什么样的AI,得当在当地跑,什么样的AI,得当在云端跑,什么样的AI,直接网页上用就行了。。。
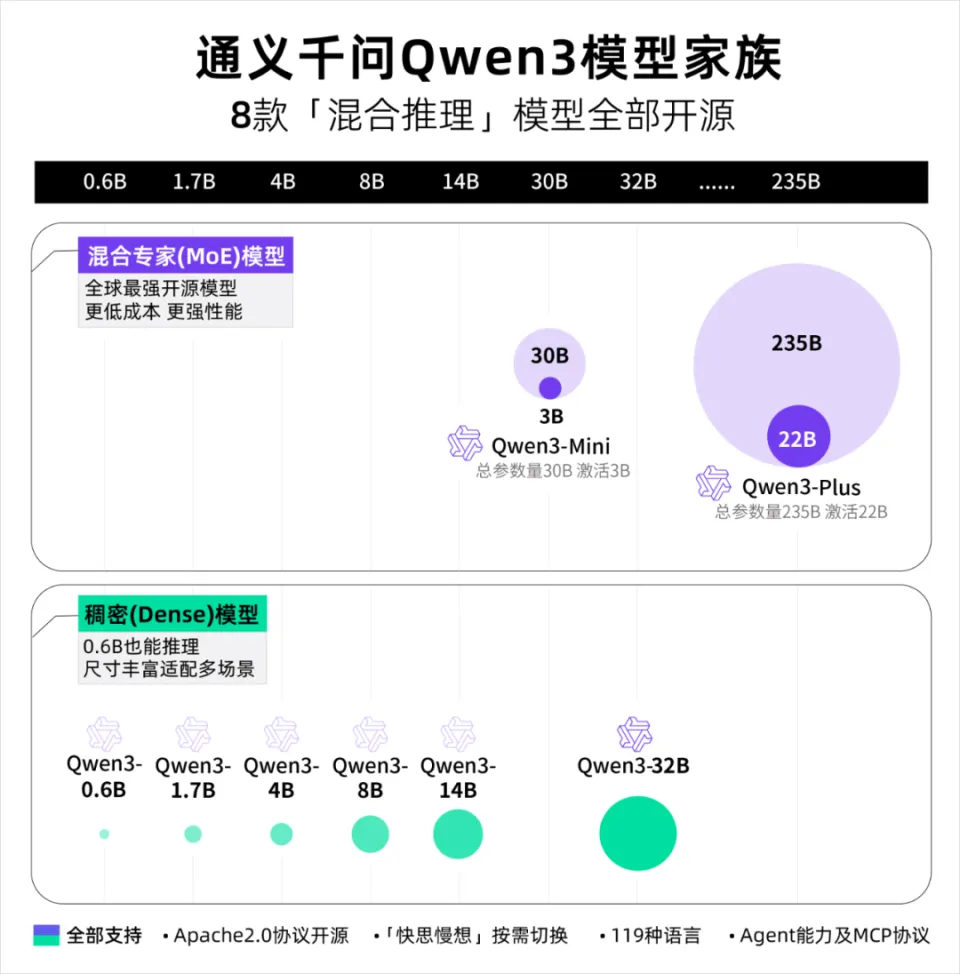
模型 的参数目种类有很多很多,1.5B,8B,14B,32B... 比如Qwen家的,参数一堆。
哪些能在当地跑,哪些不能在当地跑,要搞清晰这个,我们起首得做点小学二年级数学题.... B全称为Billion,十亿。 1B的模型 就阐明有10亿个参数,一个全精度的参数为4个字节,那么1B的模型 为40亿字节。 1GB恰好为10亿个字节,也就是说,跑一个1B的参数必要4GB的显存。 但是对于大模型 推理来说,全精度(FP32)太糟蹋 资本 了,所以大多数,我们会跑半精度(FP16)大概INT8量化的模型 ,也就是一个参数占2个字节大概1个字节。 这样,跑一个1B的参数只必要2GB显存,跑一个8B的参数只必要16GB显存。 固然在推理的时候,还必要肯定的显存做上下文缓存,但是加上量化,推理优化等等办法 ,当地16GB显存跑一个8B的模型 还是OK的。 比如说,前两天DeepSeek在qwen3-8B蒸馏出的deepSeek-R1-0528-Qwen3-8B模型 可以完完整 全体 署在当地跑。 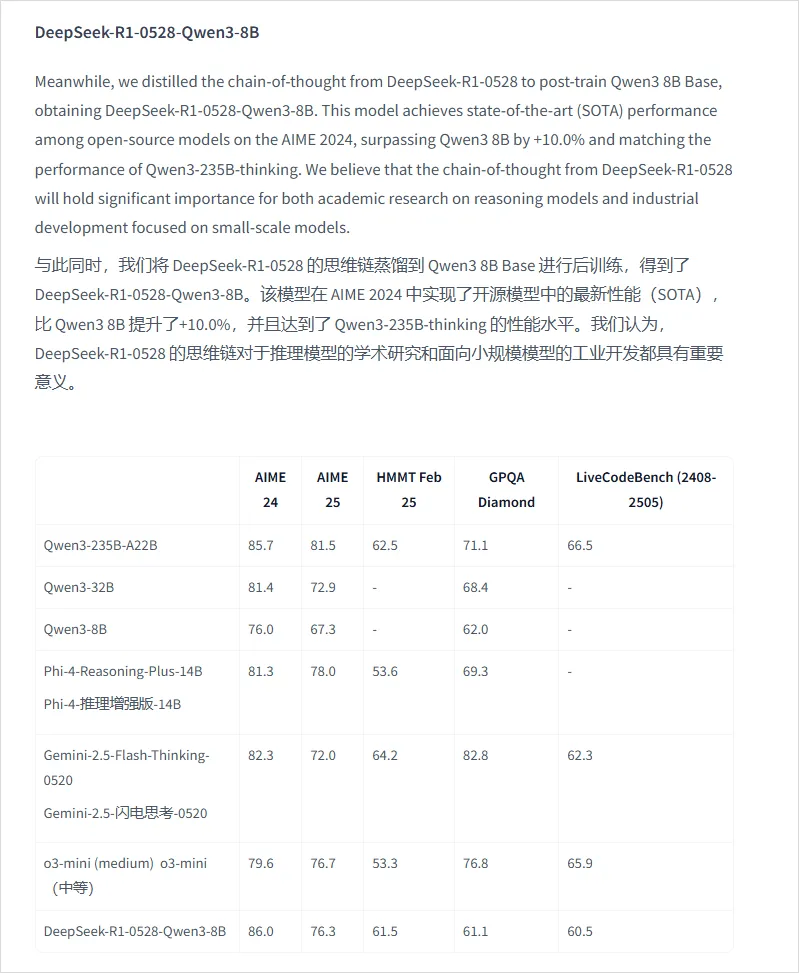 有了这个概念之后,你就会知道,固然当地部署大语言 模型 的办法 多种多样,不管是ollama,还是LM studio,大概vllm,你只必要存眷 三点: 1. 模型 的参数目。 2. 模型 是否量化。 3. 你的显卡显存。 基本 上,14B及以上的模型 跑在当地还是很贫困,比如一个INT8的14B模型 ,我在5080上跑,很慢,而且留给KV缓存的空间很少,真要跑,还是4090大概5090会好一些。 14B以下的模型 ,必要你自己评估一下参数目以及显存的大小。 上面谈到的都是语言 模型 ,那么图像模型 ,视频模型 ,音频模型 ,3D模型 呢,其实基本 差不多,一样的道理。 比如大家都认识的ComfyUI,一个强大的临盆 力对象 ,可以天生图像,视频,音频,3D模型 ;但是在当地使用ComfyUI的条件是,你的显卡得hold得住这些模型 。 ComfyUI官方推荐了一些模型 ,这些模型 参数目多少 ,必要多少 显存我都列在了这里。 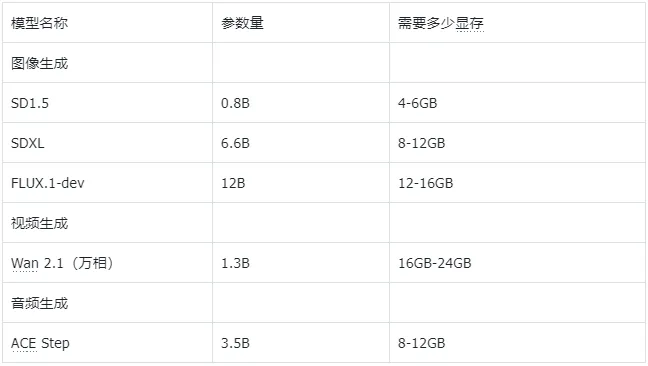 上面说了这么多,你肯定对什么样的配置能在当地跑模型 ,有一些自己的想法了。 但是这时候你大概又会问,当地跑模型 到底有哪些好处,为什么非得跑在当地啊,我去网页上用不喷鼻 么? 所以这里要说的,就是隐私安全 与合规性题目了,如果你有很重要的数据不盼望泄漏大概出现在别人和模型 的对话中,比如商业机密,医疗数据等等,那么你只能选择当地部署一个模型 。 当地部署模型 绝对不会出现数据泄漏的题目,因为所有的计算都在你自己的电脑上完成,除此之外,没有任何的请求,所以当地部署的模型 ,不用 联网也能用。 举个例子,我们都知道知识 库这个东西 ,我们也有很多教程,比如用Dify、扣子、ima啥的来搭自己的知识 库。 你当然有很多很多的内容,可以扔上去,但是如果,是你自己公司的原料 呢?如果是你的隐私数据呢?你敢扔上去吗? 比较最最核心的模型 服务,都是在人家那,隐私掩护,是最最核心的,没有之一。 但是你又有AI辅助的需求,你就只能选择当地部署,没有别的办法。 举个例子,《流离地球3》的脚本,你动头脑想,都能知道,这玩意保密性有多强,一个影戏上映前,脚本泄漏,就是最恐怖的事情,但是我们当然有需求,针对脚本举办 一系列未来视觉化的工业化AI辅助和流程。 这玩意我们敢扔到任何所谓的什么ChatGPT、Gemin、Claude、DeepSeek、元宝、豆包上吗,敢扔那就是疯了。 所以只能部门搭当地用5090D来推理,部门找云服务厂商合作。 但是如果是个人使用,其实也不必要5090D这种级别的卡,5060ti大概5070其实也就差不多了。 你像豆包PC版,就跟英伟达一块,搞了个当地知识 问答。 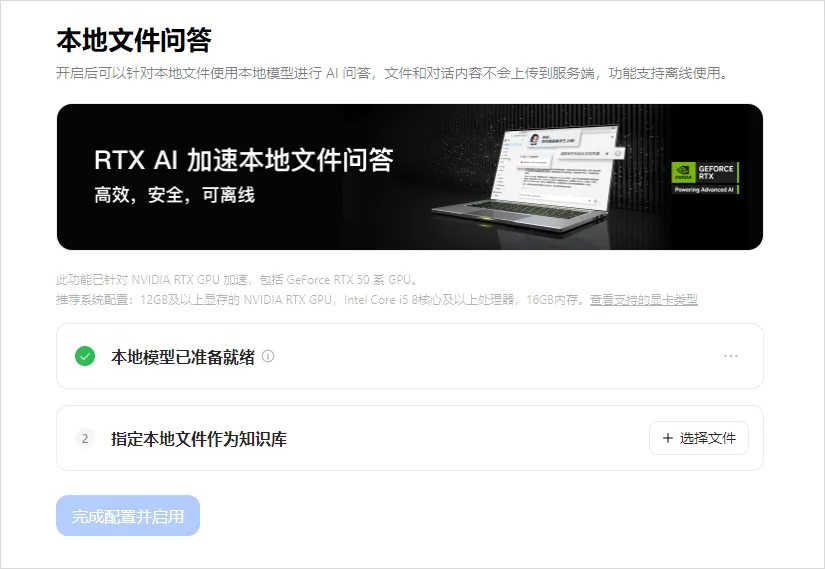 就是为了解 决隐私的当地知识 库的需求。 下载下来的模型 是个7B的,推荐使用12G以上的显卡去用,基本 也就是5060ti以上了。 不过有个好玩的是,这个7B的模型 ,是智谱的GLM-4。。。 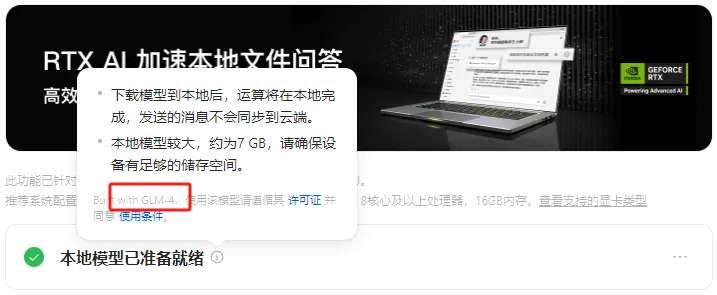 当然你也可以用Ollama啥的自己来部署,就是贫困一些。 当地部署尚有一个上风,就是一旦部署,无限免费使用。 比如用ComfyUI任意跑,任意roll,无耽误,无排队,最最重要的是,再也不用 积分焦虑了。 但是话又说返来了,由于当地受限于算力的题目,参数目太大的模型 跑不了,但参数目更大的模型 意味着更好的体现,更广的知识 面,更稳固的输出。 如果你是一个企业的负责人,必要为员工配置大模型 ,但又不盼望隐私泄漏出去,其实我更推荐的就是,可以选择在云端(火山引擎、阿里云等云服务厂商)部署大模型 ,比如Qwen2.5 72B(必要4张 48GB显存的显卡)。 如果只是自己偶尔用一用,也不涉及隐私数据啥的,其实像我一直推荐的AutoDL之类的也不错,你可以直接去租一下服务器暂时用。 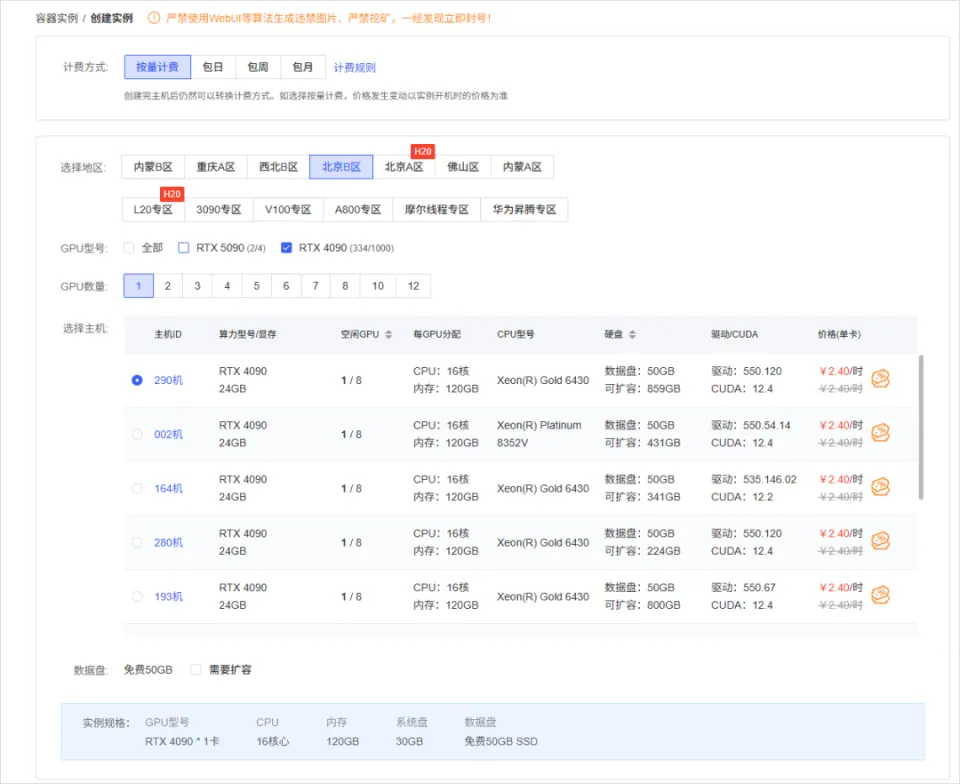 以上,看完了以后 ,我以为对于你是否必要一台能玩AI的设备,现在有了一个非常 明白的判断了。 如果你明白了,你确切 必要一台的当地设备的话,我也推荐几个618值得买的笔记本,现在都尚有货,且我自己以为不错的(非优点相关)。 台式机我就不推荐了,台式机大家还是自己攒吧,5060Ti、5070、5070Ti都可以,当然你如果 预算充足,上5080和5090D也没啥题目。。。 主如果 推荐几款笔记本(我自己主不雅观 意见)。 按你的预算价位分别。 5000元档。 机械革命极光X,5060 8G+i7-13700HX,国补完5332,性价比拉满。 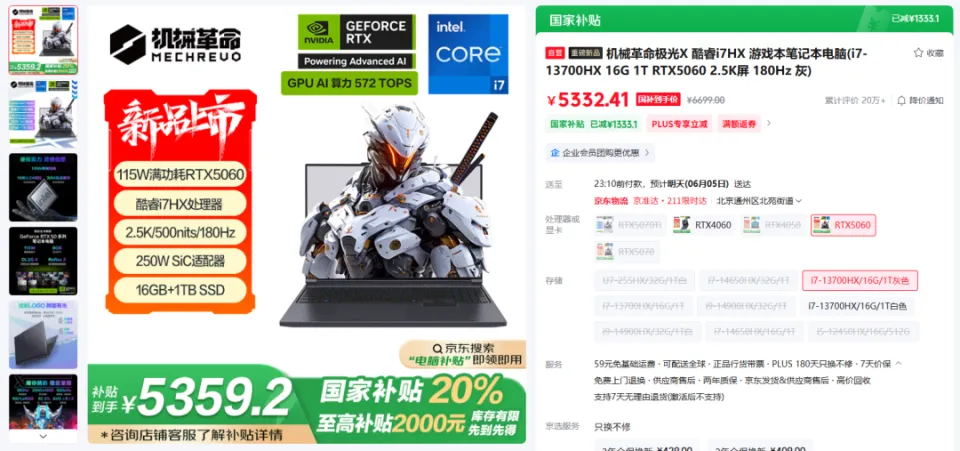 6000元档。 无脑HP阴影 精灵11,5060 8G+i7-13700HX,原价7799,现在6208。 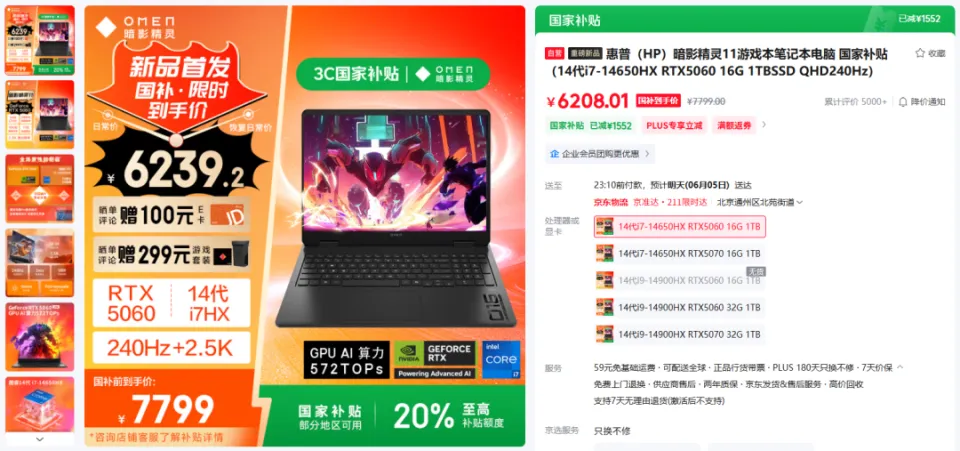 7000元档。 依然HP阴影 精灵11,显卡进级 成5070,加了800块钱,原价8699,现在到手价6959。 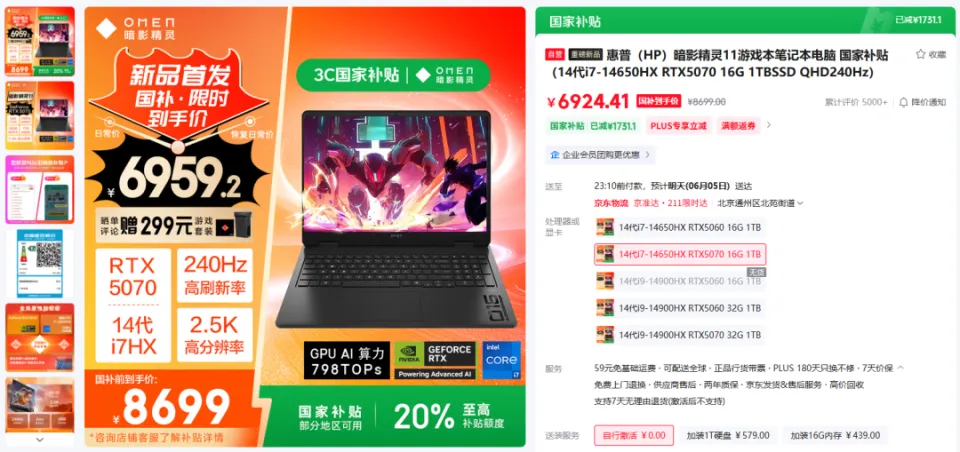 华硕天选6 Pro 锐龙版,5070 12G+8940HX,原价9499现在国补完7599。  说实话,我自己已经很久不买intel的CPU了,从20年开始,我换的电脑的CPU全是AMD的,还记得我20年换的本就是华硕天选2锐龙版,当时候疫情困在家里一直爽玩命运2,现在那台天选2已经是我妈的专属了。 8000元档。 想买5070Ti,直接上机械革命蛟龙吧,5070Ti 16G + R9-8945HX,原价10499,国补打折完7873,8000不到5070Ti带回家。 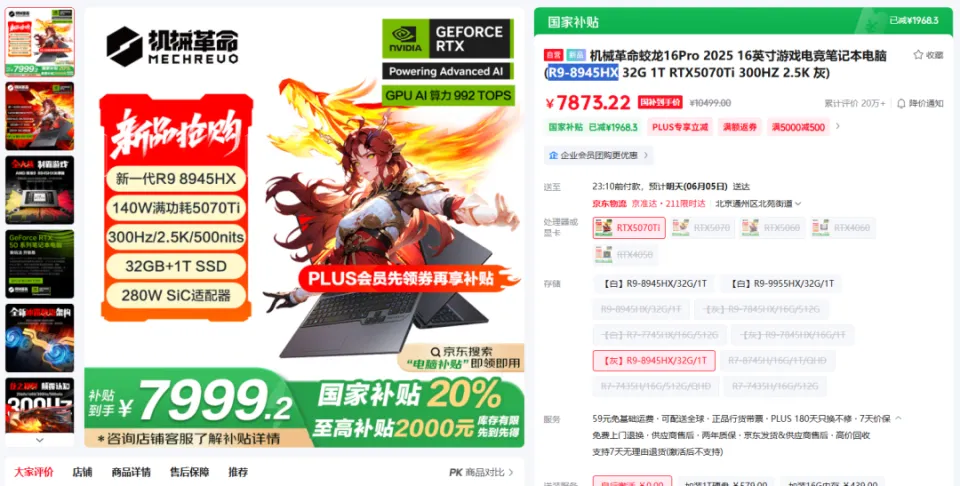 以上,自行去京东搜索就行。 当然,如果你们也想看看其他的搭载了50系显卡的笔记本,也可以去英伟达的这个网页里面看,里面非常 的全,基本 都列出来了。 https://pro.jd.com/mall/active/2UBbPZExaeXMVFrAp8FMfNUJ9SfK/index.html
大家有更好更推荐的,也接待评论区打出来,大概尚有什么618值得买的小玩意。 盼望这篇文章。 对大家,有一些帮助。 以上,既然看到这里了,如果以为不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。 >/ 作者:卡兹克、悟空 >/ 投稿或爆料,请联系邮箱:wzglyay@virxact.com |


2025-05-03
2025-03-05
2025-02-26
2025-03-05
2025-02-26


官方手机版

微信公众号

商务合作