新智元报道 编辑:LRS【新智元导读】20万次模拟实行,耗资5000美元,证实年夜 模型 在多轮对话中的体现明显 低于单轮对话!一旦模型 的第一轮答案出现毛病,不要试图改正,而是新开一个对话!ChatGPT将年夜 模型 技

新智元报道 【新智元导读】20万次模拟实行,耗资5000美元,证实年夜 模型 在多轮对话中的体现明显 低于单轮对话!一旦模型 的第一轮答案出现毛病,不要试图改正,而是新开一个对话!ChatGPT将年夜 模型 技巧 鞭策 到「对话」场景,直接激发 了AI技巧 的爆炸式增加 。 用户可以先提出一个粗糙 的、不明确的题目,再根据模型 的回答逐步完善指令、补充细节,多轮对话也催生出「跟AI打德律风 」等幽默 的运用 计划。 不外,现有的年夜 模型 性能 评估基准仍旧是基于单轮对话机制,输入的指令也更长,信息更完善,其在真实场景中多轮对话的性能 仍旧没有得到很好地评估。 最近,研讨 职员举行了一场超过20万次的多轮对话模拟实行,对比了15个顶级开源和闭源年夜 模型 在单轮和多轮对话场景中的性能 差别,结果发现,所有模型 在多轮对话中的体现都明显 低于单轮对话,平均性能 在六种天生任务中下降了39%  论文链接:https://arxiv.org/abs/2505.06120 简单来说,年夜 模型 通常 在第一次回答题目的时间,就已经定下了基调,过早地实行天生终极办理方案,并且 在后续回答的时间也会依赖这个结论。 性能 下降后,年夜 模型 的靠得住 性也明显低落,研讨 职员将这种征象称之为「对话迷掉 」,即LLMs在多轮对话中一旦走错了方向,在后续提示中添加信息也无法改正,也就没办法规复到精确的问答路径。 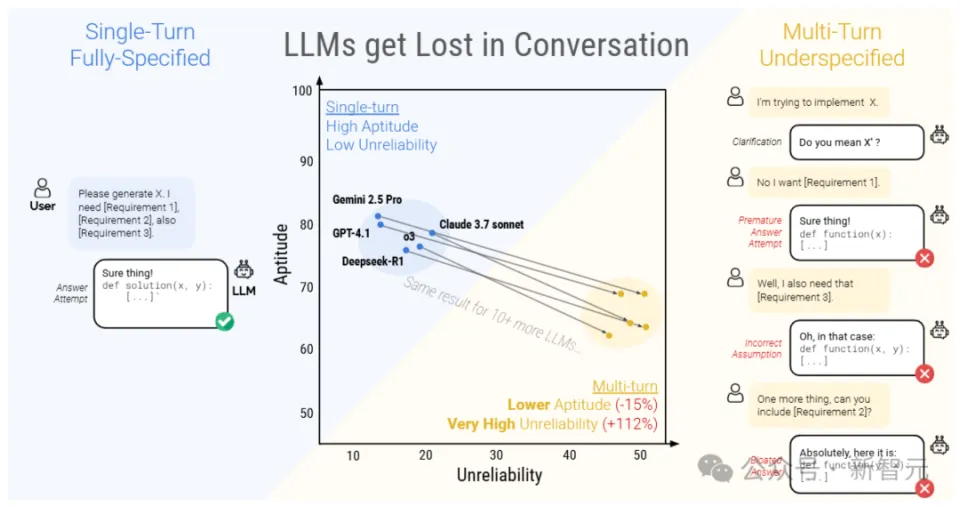  研讨 职员将现有的单轮基准测试任务重新计划为多种范例的多轮模拟对话场景,以评估年夜 型说话 模型 (LLMs)在多轮、不明确对话中的体现。
GSM8K数据会合详细的(fully-specified)指令文本很长,包括背景、条件、题目等等。 研讨 职员将原始指令接纳一个「半自动化流程」举行切分,每个分片包罗原始指令中的一个元素,分片1是指令的高等 意图,模拟用户的第一次输入,后续的分片则对意图细节举行澄清。 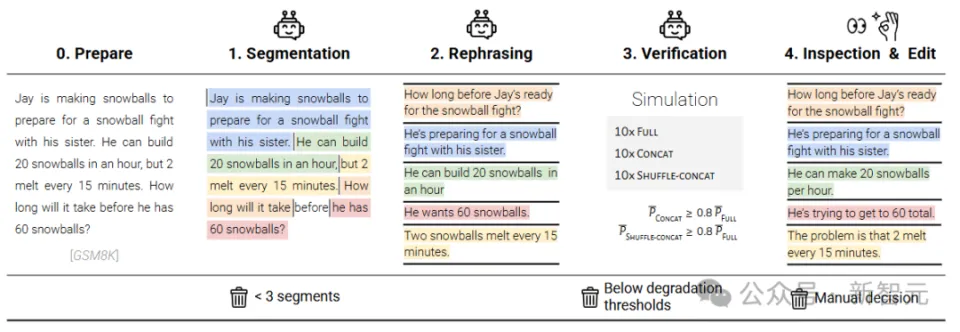 所有分片合在一起,可以表达出与原始指令类似的信息,分片必需 满足五个要素:信息保存、清晰的原始意图、序次无关(除第一个分片外,其他分片相互自力 )、最年夜 化分片(尽可能从原始指令中提取信 息)、最小化转换(坚持 原始指令的作风 ,制止简化)。 
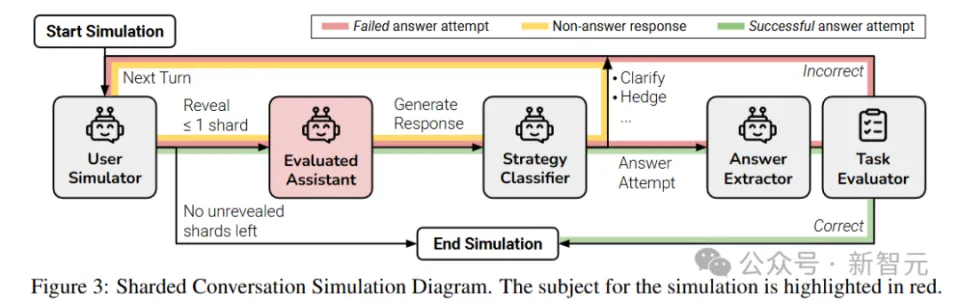 基于分片指令模拟多轮、不明确对话的过程 对话包括三个脚色:
在第一轮对话中,用户模拟器向助手显现 指令分片1,助手随后天生文本回答。 系统 会将助手的回答归类为七种可能的回应计谋之一:澄清、拒绝、回避、扣问、讨论、缺掉 或实行回答。 如果助手给出了一个明确的、完整的办理方案,就挪用 「答案提取组件」来肯定 助手回答中对应答案的部分(比方代码片断或数字),主如果 由于年夜 模型 通常 会在答案中添加额外信息,好比自然说话 解释或后续题目,可能会干扰评估结果。 在后续每一轮对话中,用户模拟器最多输入一个分片信息,然后助手的回复范例为「实行回答」,则举行评估。 如果任务评估器认为 助手的答案实行是精确的,或是分片数据耗尽,则多轮对话模拟竣事。 研讨 职员使用一个低资本的年夜 模型 (GPT-4o-mini)来实现用户模拟器,可以或许访问全部 分片指令以及到现在为止的对话状态 ,并负责对分片数据举行重新措辞,以自然地融入对话中。 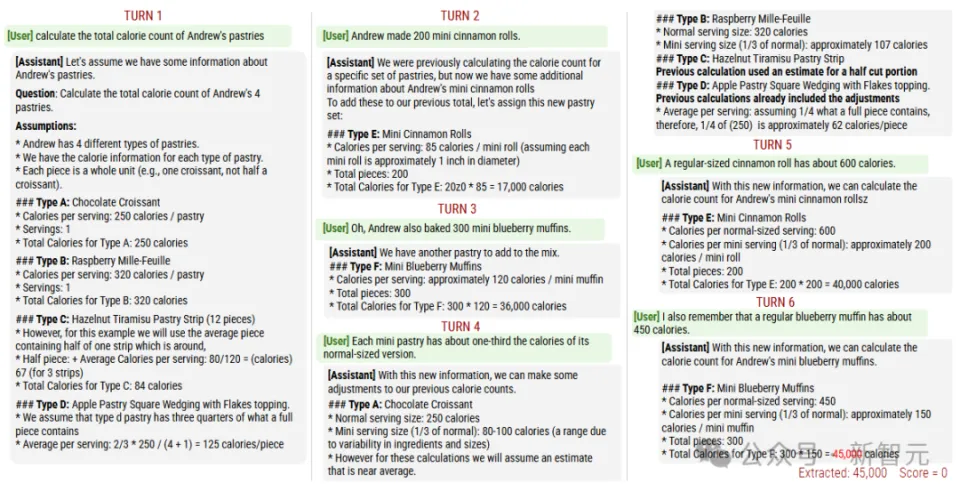 除了用户消息外,助手在第一轮对话之前还会收到一个最小化的系统 指令,供给 完成任务所需的高低 文,包括数据库架构或可用API工具列表等。 助手并不知道自己正处于多轮、不明确的对话中,也没有偏好特定的对话计谋。 固然额外的指令可能会转变 模型 的活动,但研讨 职员认为 这种厘革并不现实,由于在实际场景中,用户也不可能会考虑输入这些信息。 计谋分类器和答案提取器组件也使用基于提示的GPT-4o-mini实现。 固然在模拟器中使用基于LLM的组件可以让对话加倍 动态,从而供给 更真实的模拟,但不可制止地会导致模拟毛病 ,可能会影响实行的有用性。
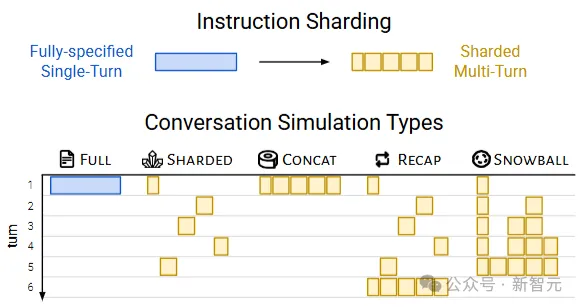 完全指定(fully-specified, Full),模拟单轮对话场景,即原始指令在第一轮就完整地供给 应 LLM,用于评估模型 的基础性能 。 分片(sharded),模拟多轮、不明确的对话。 归并(concat)模拟基于分片指令的单轮、完全指定的对话。 所有分片被归并成一个单轮指令,以bullet-point情势呈现(每行一个分片),并在前面加上一条指令,要求LLM综合所有信息来完成任务。 concat模拟是完全指定和分片之间的逻辑中心点,消除了不明确性,但保存了在分片过程中出现的指令重新措辞。 如果一个模型 在full和concat模拟中都能成功完成任务,却无法在分片模拟中完成,就可以认为 模型 体现不佳 的原因 ,不是由于分片过程中的信息丢掉 题目,而是源于对话的不明确性和多轮性子。 总结(recap)模拟分片对话,并在末了增加 了一个总结轮次,将所有分片指令在一轮中重新陈述,给LLM末了一次回答的机会,可以评估「智能体」式干涉 能否缓解分片对话中性能 下降的题目。 滚雪球(snowball)要求模型 对每轮对话都举行总结。 在每一轮中,用户模拟器不仅引入一个新的分片,还会重新陈述到现在为止对话中已经输入的所有分片,从而产生「滚雪球」效应,即每轮对话都包罗之前所有轮次的信息,再加上一个新的分片,可以评估每轮对话中的「提示」是否有助于缓解LLM在多轮对话中的掉 忆题目。 研讨 职员使用了600条指令,针对三种主要模拟范例(full, concat, shared),从八个模型 家属中选择了总共15种LLMs()举行了实行,每种模型 与每种模拟范例的组合都运行10次模拟,总共举行了超过20万次模拟对话,总资本约为5000美元。 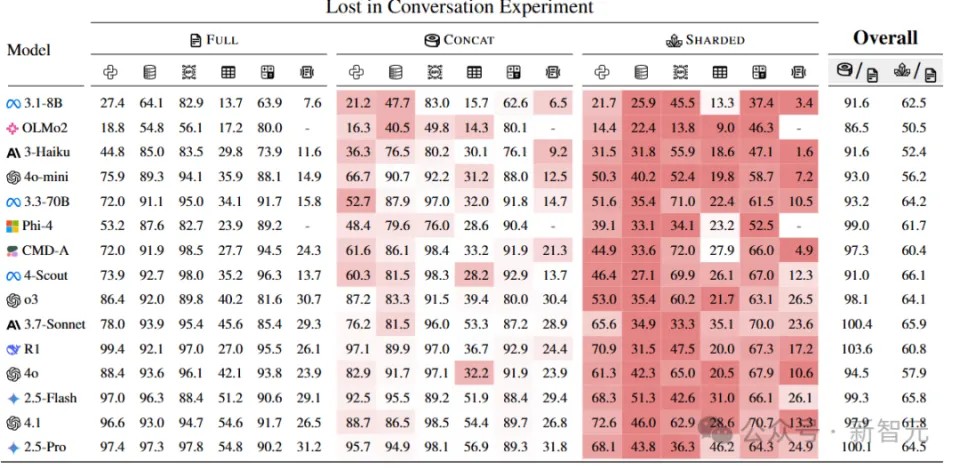 从总体上看,每个模型 在举行「完全指定」和「分片对话」时,在每项任务中的体现都有所下降,平均下降幅度为39% 研讨 职员将这种征象称为「对话迷掉 」,即在完全指定、单轮对话的实行室情况中体现精彩(90%以上)的模型 ,在更靠近现实的场景(对话不明确且为多轮)中,类似任务上体现不佳 。 相比 之下,在归并concate设置中,模型 的体现年夜 致相当,其平均体现达到 了完全指定体现的95.1%,也就意味着分片对话中体现下降的原因 并不是由于分片指令可能导致的信息丢掉 ,否则归并对话的体现也会响应 低落。 还可以不雅观 察到,较小的模型 (如Llama3.1-8B-Instruct、OLMo-2-13B、Claude 3 Haiku)在归并对话中的体现下降更为明显 (86%-92%),表白 较小的模型 在泛化本领上不如较年夜 的模型 ,即使是重新措辞也会对模型 性能 产生较年夜 影响。 别的,增加 测试时的计算 量(推理token)并不能帮助模型 应对多轮不明确对话。 实行中的两个推理模型 (o3和Deepseek-R1)性能 下降与非推理模型 类似,也证实了仅靠增加 测试时的计算 量并不能让模型 在多轮对话中订定计谋。 推理模型 偏向 于天生更长的回答(平均比非推理LLMs长33%),同时会肴杂模型 认知,使其分不清用户提出的要乞降 自己在上一轮对话中的思索。 |


2025-05-03
2025-03-05
2025-02-26
2025-03-05
2025-02-26


官方手机版

微信公众号

商务合作