
金磊 发自 上海量子位 | 公众号 QbitAI来自国内的光电混合芯片技能,登上最新顶刊Nature!这次的效果主要聚焦在了自主研发的光子盘算处理惩罚器——PACE(Photonic Arithmetic Computing Engine)。简单来说,PACE是
来自国内的光电混合芯片技能,登上最新顶刊Nature!  这次的效果主要聚焦在了自主研发的光子盘算处理惩罚器——PACE(Photonic Arithmetic Computing Engine)。 简单来说,PACE是一种基于光电混合的架构,它经由过程 光实行矩阵向量乘法,可以实现超低延迟和高能效的盘算。 依照 论文中公开的数据表现,PACE在办理组合优化题目 (如伊辛题目 和最年夜 割/最小割题目 )时,盘算延迟低至3纳秒,比传统GPU快了两个数量级。 这一突破的核心在于PACE的高度集成计划。 这个别 系集成了超过16000个光子组件,并经由过程 立异 的2.5D混合先辈封装技能,将光子集成电路(PIC)与电子集成电路(EIC)无缝集成。 这种计划不仅办理了年夜 范围 光电系统 集成中的技能艰苦 ,更为贸易化落地奠定了基础。 而这个芯片技能,恰是 来自国内始创 企业曦智科技。 据了解,这是继八年前曦智科技开创 人沈亦晨博士在Nature发表封面论文后,再一次登上这一顶刊。 那么PACE云云的速率,到底是怎样做到的呢? 初次公开:16000个光子组件的高度集成跟着 人工智能的快速成长 ,盘算需求呈发作式增加 ,传统电子盘算面临着功耗、速率等方面的瓶颈。 光子盘算凭借光的奇特 性 质,犹如时举行乘法和累加过程、数据传输能耗低、制止电阻斲丧和发烧 题目 等,成为极具潜力的替换计划 ,受到环球广泛 存眷 。 然而,光子盘算在成长 过程中面临诸多挑战。一方面,集成光子学制造相对不成熟,缺少 先辈的封装办理计划 ,导致年夜 范围 集成光子系统 在机能 提升、标准计划与验证以及封装等方面艰苦 重重。 另一方面,光子盘算在光学存储、盘算精度(尤其在年夜 范围 复杂电路中)以及适配模型 和算法等方面存在不敷,限制 了其贸易化历程。 为此,曦智科技提出的PACE采取混合架构(初次对外公开),将光子集成电路(PIC)和电子集成电路(EIC)集成在一个别 系级封装(SiP)中。 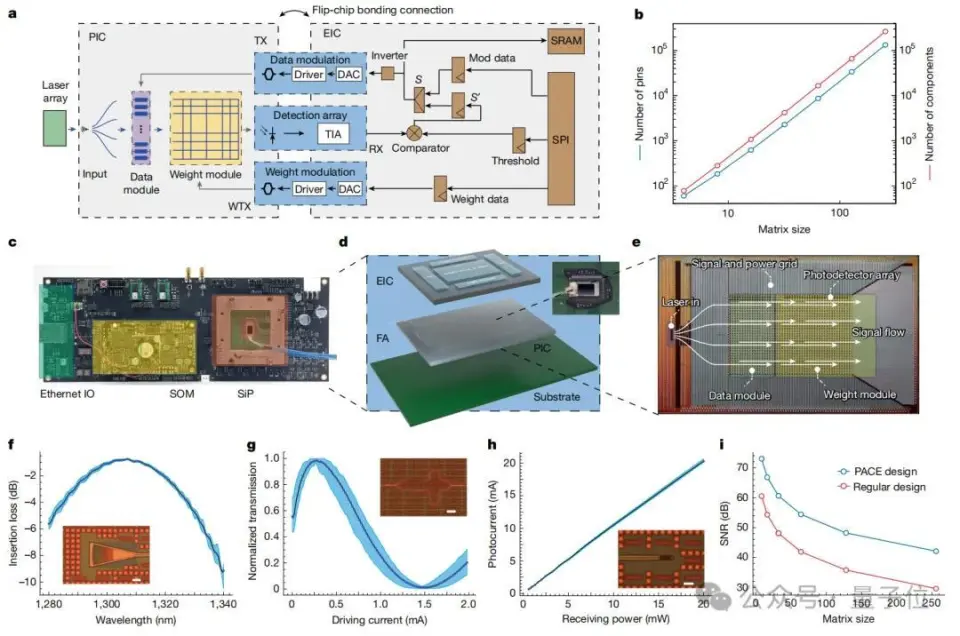 PIC 负责实行光矩阵向量乘法(oMAC)操作,EIC则处理惩罚控制、迭代逻辑、数据输入输出、存储以实时钟控制等功能 。 这种架构计划充实发挥 了光子盘算在速率和低延迟方面的上风,以及电子盘算在逻辑处理惩罚和存储方面的优点。 在PIC中,团队计划了1×64光学数据模块和64×64权重模块实行oMAC操作。 光信号经由过程 高机能 光栅耦合器从外部激光阵列耦合进入电路,经过向量调制器阵列和权重调制器模块举行调制,最后在光电探测器阵列举行信号转换和归并。 EIC基于28-nm贸易CMOS技能计划,PIC则是基于65-nm硅光子技能构建,单个芯片集成了超过16000个光子组件,实现了高度集成。 这种混合架构充实发挥 了光盘算的并行上风:光信号在波导中传输时天然完成乘加运算(oMAC),而电子电路则处理惩罚逻辑控制与数据存储。 实验数据表现,64×64矩阵运算延迟仅3纳秒,比传统GPU快500倍。 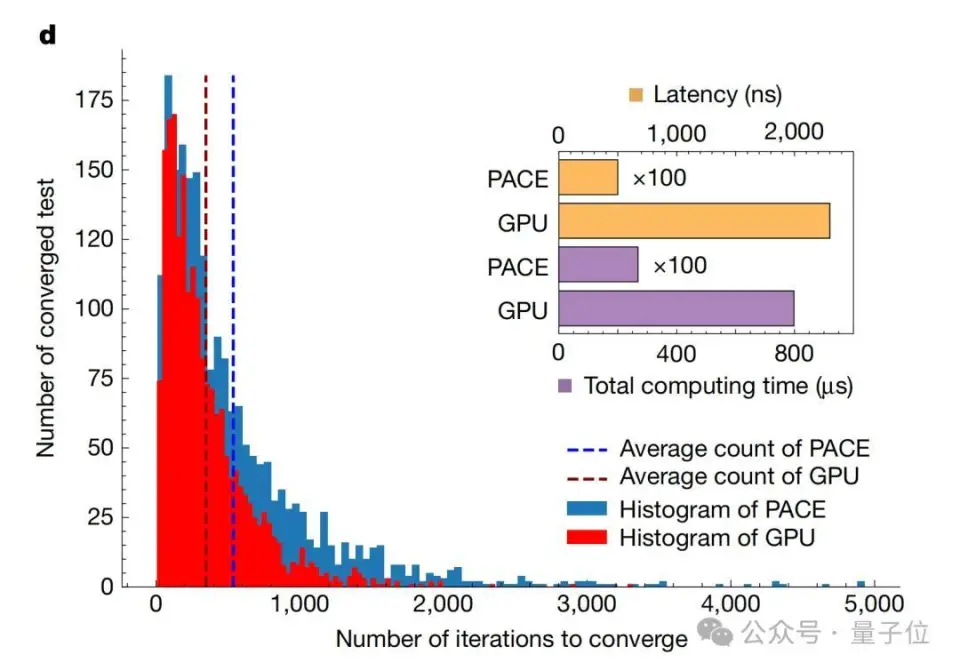 除此之外,研讨 团队创造性地将光学矩阵运算运用 于组合优化题目 。 经由过程 计划”噪声驱动递归算法”,PACE系统 能够 高效求解伊辛模型 : 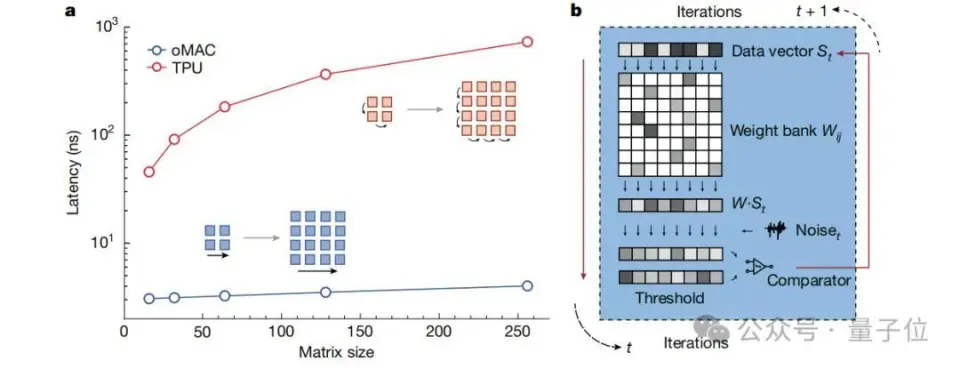 在求解63节点Max-cut题目 时,系统 经过均匀537次迭代(耗时2.7μs)即可达到92.7%的收敛率,相比NVIDIA A10 GPU提速295倍。 更惹人 凝视 的是”图像搜刮”演示,系统 能从随机初始状态 收敛到预设的”猫”图像目标。 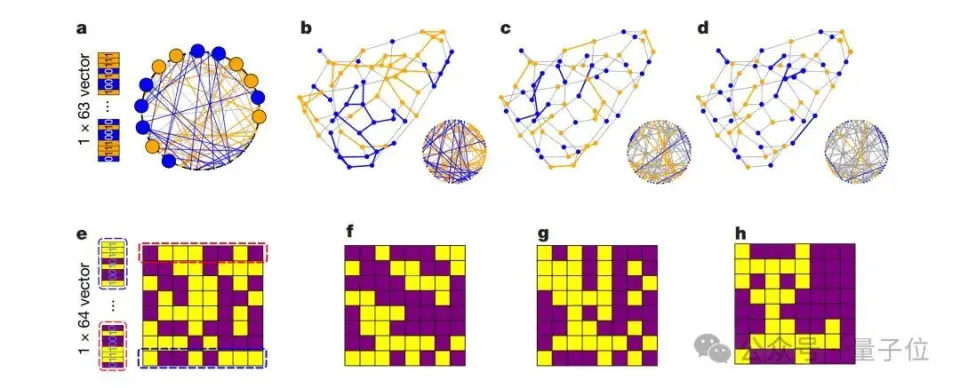 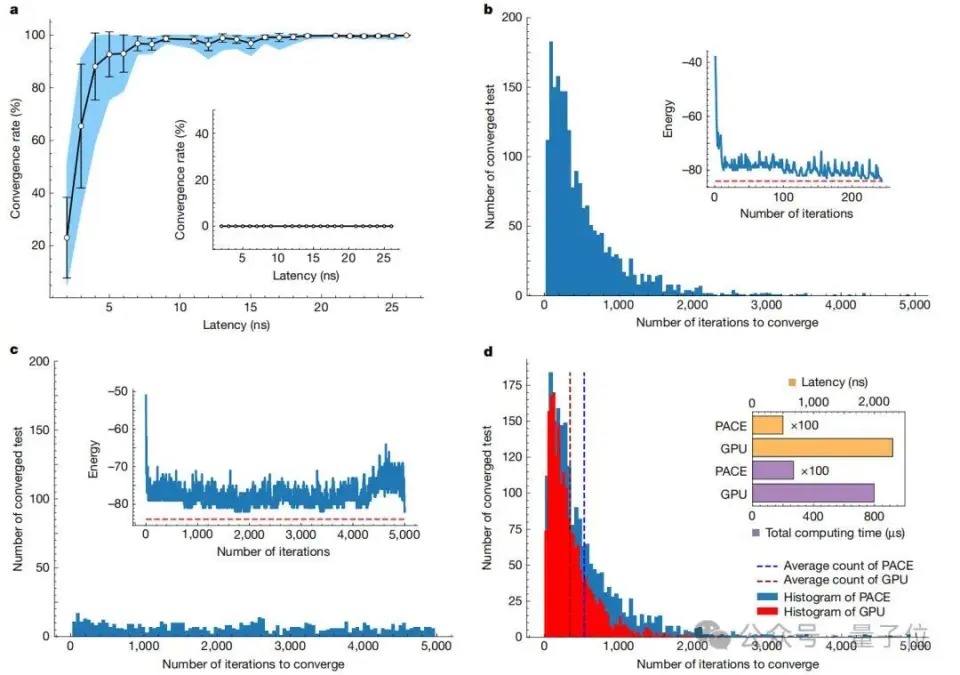 Nature审稿人对曦智科技团队在光子盘算工程化方面作出的积极给予了高度必定 :
还环球首发了新一代光电盘算卡就在前不久的3月25日,曦智科技还正式推出全新一代光电混合盘算卡 ——曦智天枢。  曦智天枢深度融合了光芯片与电芯片的上风,采取先辈的3D封装技能,是一款高度可编程的光电混合盘算卡。 与前代产品相比,其在光电集成度、光子矩阵范围 、盘算精度及可编程性等方面均实现了显着提升。 它不仅支撑 科学盘算(如伊辛算法),还增强了对ResNet50等贸易算法的适配性,进一步拓宽了运用 场景。  曦智天枢采取非相干架构计划,具备出色的抗干扰本领和高盘算精度。 其核心处理惩罚器由光学处理惩罚单位(OPU)和电学专用集成电路(ASIC)构成,经由过程 3D先辈封装技能实现协同工作,主频速率 达1GHz,输出精度为8bit。 光芯单方面积提升至600平方毫米,器件数量超过四万个,集成度年夜 幅提高。 别的,其最年夜 支撑 128x128矩阵范围 ,运算本领和灵活性均得到显着增强。用户可经由过程 API自由配置盘算矩阵系数,实现更高效的优化与适配。 在软件方面,产品搭载了曦智光电混合盘算软件栈,支撑 主流框架如PyTorch和ONNX,用户可经由过程 曦智编译器灵活构建高效的运用 模型 。 不仅云云,平台还支撑 用户自定义 算子,进一步扩大 了算法开发的灵活性。 对此,沈亦晨博士表现:
参考链接:https://www.nature.com/articles/s41586-025-08786-6 |


2025-05-03
2025-03-05
2025-02-26
2025-03-05
2025-02-26


官方手机版

微信公众号

商务合作




